In this post, we shed some light on the adjoint state method as used in the famous “Neural ODE” paper [1].
In Section 1, we start by introducing the adjoint state method in its raw form (ODE, loss minimization, adjoint equations), in continuous time (denoted by [C]). If this is already clear to you, then… no need to read the rest of the post! You’re already an adjoint master. Otherwise, please stick with me as we will derive an analogous procedure in discrete time (denoted by [D]) in Section 2, where things are more intuitive.
1. Continuous time: Adjoint method
Consider a system that evolves in continuous time and is in state 
![{t\in[0,1]}](https://s0.wp.com/latex.php?latex=%7Bt%5Cin%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=1&c=20201002)
![\displaystyle \mathrm{[C] \ State \ dynamics:} \quad \frac{\mathrm{d}}{\mathrm{d} t} x_t = f_t(x_t;\theta), \quad \forall \, t\in[0,1] \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7B%5BC%5D+%5C+State+%5C+dynamics%3A%7D+%5Cquad+%5Cfrac%7B%5Cmathrm%7Bd%7D%7D%7B%5Cmathrm%7Bd%7D+t%7D+x_t+%3D+f_t%28x_t%3B%5Ctheta%29%2C+%5Cquad+%5Cforall+%5C%2C+t%5Cin%5B0%2C1%5D+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=1&c=20201002)
Note that 

A notation remark: 





1.2. Loss minimization
We want to minimize a penalty 

Observe that the loss depends on 
1.3. Adjoint equations
We now want to compute the gradient of 

![\displaystyle a_t := \frac{\partial \mathcal L}{\partial x_t}, \qquad \forall \, t\in[0,1] \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+a_t+%3A%3D+%5Cfrac%7B%5Cpartial+%5Cmathcal+L%7D%7B%5Cpartial+x_t%7D%2C+%5Cqquad+%5Cforall+%5C%2C+t%5Cin%5B0%2C1%5D+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=1&c=20201002)
which satisfies the following ODE:
![\displaystyle \mathrm{[C] \ Adjoint \ dynamics:} \quad \frac{\mathrm{d}}{\mathrm{d} t} a_t = -a_t \frac{ \partial f_t}{\partial x_t}(\bar{x}_t;\bar{\theta}), \qquad \forall \, t\in[0,1] \ \ \ \ \ (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7B%5BC%5D+%5C+Adjoint+%5C+dynamics%3A%7D+%5Cquad+%5Cfrac%7B%5Cmathrm%7Bd%7D%7D%7B%5Cmathrm%7Bd%7D+t%7D+a_t+%3D+-a_t+%5Cfrac%7B+%5Cpartial+f_t%7D%7B%5Cpartial+x_t%7D%28%5Cbar%7Bx%7D_t%3B%5Cbar%7B%5Ctheta%7D%29%2C+%5Cqquad+%5Cforall+%5C%2C+t%5Cin%5B0%2C1%5D+%5C+%5C+%5C+%5C+%5C+%284%29&bg=ffffff&fg=000000&s=1&c=20201002)
where 



![\displaystyle \mathrm{[C] \ Loss \ gradient:} \quad \frac{\partial \mathcal L}{\partial \theta} = \int_0^1 a_t \frac{\partial f_t}{\partial \theta}(\bar{x}_t;\bar{\theta}) dt. \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7B%5BC%5D+%5C+Loss+%5C+gradient%3A%7D+%5Cquad+%5Cfrac%7B%5Cpartial+%5Cmathcal+L%7D%7B%5Cpartial+%5Ctheta%7D+%3D+%5Cint_0%5E1+a_t+%5Cfrac%7B%5Cpartial+f_t%7D%7B%5Cpartial+%5Ctheta%7D%28%5Cbar%7Bx%7D_t%3B%5Cbar%7B%5Ctheta%7D%29+dt.+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=1&c=20201002)
Fix the current value 
- Solve the ODE (1) forward in time, e.g., with Euler’s method, starting from
- Solve the adjoint equation (4) backward in time, starting from
, to obtain
for all
- Compute the integral (5) to obtain the gradient.
where steps 2 and 3 can be carried out jointly, along a single backward pass.
If little of this is clear to you or you lack the main intuitions, no worries! This post is all about it: we will derive the same procedure in discrete time, where things are more intuitive.
2. Discrete time: Backpropagation
2.1. Discrete-time ODE formulation
To better understand the adjoint method, we construct the discrete-time counterpart of the ODE (1). We will heavily abuse of notation overload, so please bear with me. We start by defining a series of parametric functions 
![\displaystyle \mathrm{[D] \ State \ dynamics:} \quad x_{k+1} = x_k + f_{k}(x_{k};\theta), \quad 0\le k<K \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7B%5BD%5D+%5C+State+%5C+dynamics%3A%7D+%5Cquad+x_%7Bk%2B1%7D+%3D+x_k+%2B+f_%7Bk%7D%28x_%7Bk%7D%3B%5Ctheta%29%2C+%5Cquad+0%5Cle+k%3CK+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=1&c=20201002)
where 






2.2. Loss minimization
As before, our goal is to minimize the loss
2.3. Adjoint equations
We directly compute the gradient of 

In each path, we can apply the chain rule, as a cascade of two effects: i) the state 




We can then sum up the contributions of each one of the
![\displaystyle \mathrm{[D] \ Loss \ gradient:} \quad \frac{\partial \mathcal L}{\partial \theta} = \sum_{k=1}^K a_k \frac{\partial f_{k-1}}{\partial \theta}(\bar{x}_{k-1};\bar{\theta}) \ \ \ \ \ (7)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7B%5BD%5D+%5C+Loss+%5C+gradient%3A%7D+%5Cquad+%5Cfrac%7B%5Cpartial+%5Cmathcal+L%7D%7B%5Cpartial+%5Ctheta%7D+%3D+%5Csum_%7Bk%3D1%7D%5EK+a_k+%5Cfrac%7B%5Cpartial+f_%7Bk-1%7D%7D%7B%5Cpartial+%5Ctheta%7D%28%5Cbar%7Bx%7D_%7Bk-1%7D%3B%5Cbar%7B%5Ctheta%7D%29+%5C+%5C+%5C+%5C+%5C+%287%29&bg=ffffff&fg=000000&s=1&c=20201002)
where all derivatives are computed at the current value 
We can recognize that (7) is the discrete-time counterpart of (5), that we report here for convenience:
![\displaystyle \mathrm{[C] \ Loss \ gradient:} \quad \frac{\partial \mathcal L}{\partial \theta} = \int_0^1 a_t \frac{\partial f_t}{\partial \theta}(\bar{x}_t;\bar{\theta}) dt.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7B%5BC%5D+%5C+Loss+%5C+gradient%3A%7D+%5Cquad+%5Cfrac%7B%5Cpartial+%5Cmathcal+L%7D%7B%5Cpartial+%5Ctheta%7D+%3D+%5Cint_0%5E1+a_t+%5Cfrac%7B%5Cpartial+f_t%7D%7B%5Cpartial+%5Ctheta%7D%28%5Cbar%7Bx%7D_t%3B%5Cbar%7B%5Ctheta%7D%29+dt.+&bg=ffffff&fg=000000&s=1&c=20201002)
Next we study how the adjoint variables are connected with each other. Recall that 
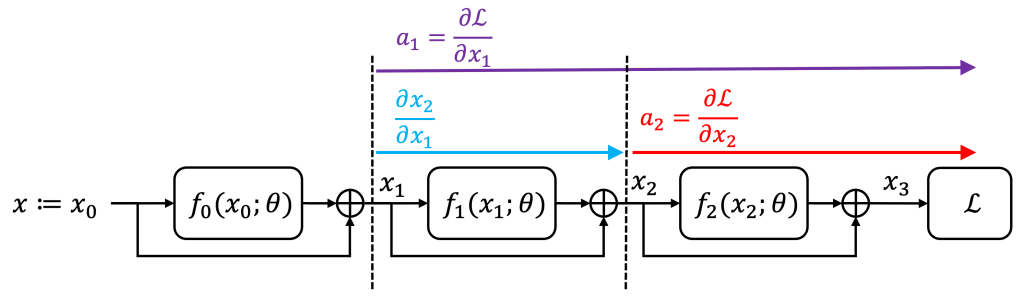

To obtain the analogous of (4), we need to express 

where 

![\displaystyle \mathrm{[D] \ Adjoint \ dynamics:} \quad a_{k+1} - a_k = - a_{k+1} \frac{\partial f_{k}}{\partial x_k}(\bar{x}_k;\bar{\theta}) \ \ \ \ (10)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7B%5BD%5D+%5C+Adjoint+%5C+dynamics%3A%7D+%5Cquad+a_%7Bk%2B1%7D+-+a_k+%3D+-+a_%7Bk%2B1%7D+%5Cfrac%7B%5Cpartial+f_%7Bk%7D%7D%7B%5Cpartial+x_k%7D%28%5Cbar%7Bx%7D_k%3B%5Cbar%7B%5Ctheta%7D%29+%5C+%5C+%5C+%5C+%2810%29&bg=ffffff&fg=000000&s=1&c=20201002)
that is the discrete-time counterpart of the adjoint ODE (4), that we report here for convenience:
![\displaystyle \mathrm{[C] \ Adjoint \ dynamics:} \quad \frac{\mathrm{d}}{\mathrm{d} t} a_t = -a_t \frac{ \partial f_t}{\partial x_t}(\bar{x}_t;\bar{\theta}), \quad \forall \, t\in[0,1].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7B%5BC%5D+%5C+Adjoint+%5C+dynamics%3A%7D+%5Cquad+%5Cfrac%7B%5Cmathrm%7Bd%7D%7D%7B%5Cmathrm%7Bd%7D+t%7D+a_t+%3D+-a_t+%5Cfrac%7B+%5Cpartial+f_t%7D%7B%5Cpartial+x_t%7D%28%5Cbar%7Bx%7D_t%3B%5Cbar%7B%5Ctheta%7D%29%2C+%5Cquad+%5Cforall+%5C%2C+t%5Cin%5B0%2C1%5D.+&bg=ffffff&fg=000000&s=1&c=20201002)
2.4. Backpropagation
We now compute the gradient
First, we need to solve the recursion (6) forward in time starting from the initial condition 
Then, in a single backward pass, we solve recursively the adjoint dynamics [D] (10) to obtain 

Backpropagation procedure:
- 0. Set
and
.
- 1. Solve the recursion (6) forward in time to obtain
- 2. Compute the final adjoint variable
.
- 3. Initialize the loss gradient
.
- 4. For
:
- 4.1. Compute the adjoint
.
- 4.2. Update the loss gradient
.
- 4.1. Compute the adjoint
- 5. Return the loss gradient
Once again, we can recognize that the backpropagation method is the discrete-time counterpart of the adjoint method in Section 1.
You’re now an adjoint master 😉
References
[1] Chen, Ricky TQ, Yulia Rubanova, Jesse Bettencourt, and David K. Duvenaud. “Neural ordinary differential equations.” Advances in neural information processing systems 31 (2018).

Leave a comment