Consider the problem of measuring the discrepancy between the distributions of two sets of samples 

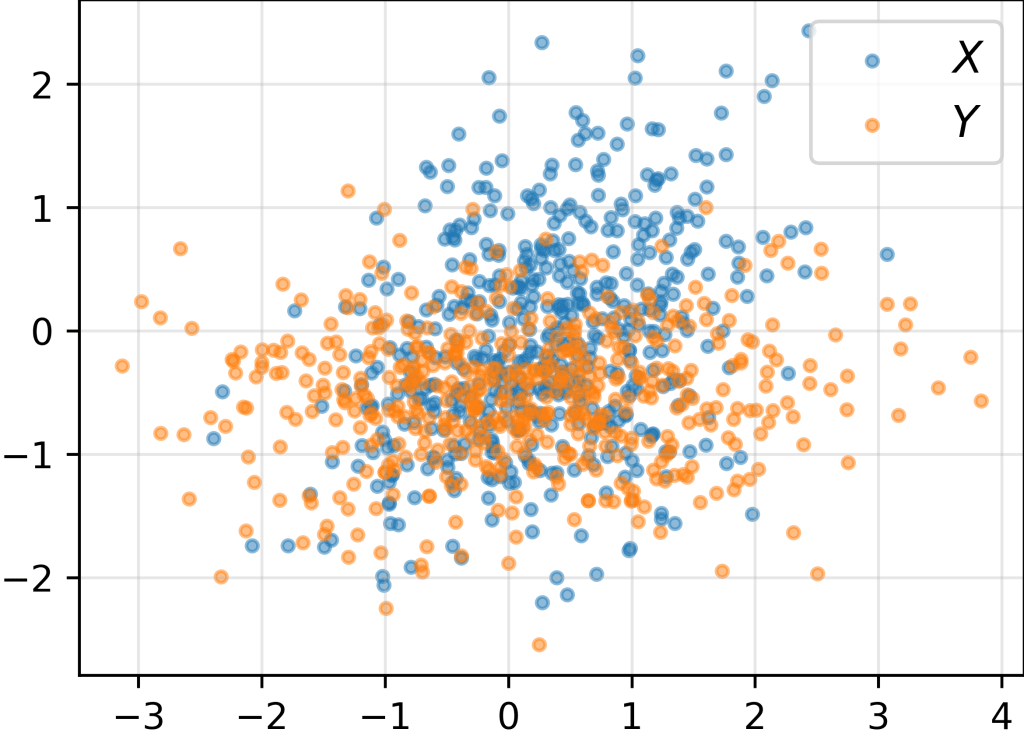
Amongst various options (KL divergence, Wasserstein distance, etc.), the Maximum Mean Discrepancy (MMD) is a beautifully elegant one, gaining popularity in recent years in the machine learning community.
In this post, instead of defining upfront the MMD in abstract terms (feature space, RKHS, etc.), we first show how to compute it in practice. Afterwards, we will unpack it to derive its formal definition. As a bonus, we will gain insights into MMD’s secret sauce: MMD can be interpreted as a measure of the dissimilarity between all moments of the two distributions.
1. MMD in practice
To compute the empirical MMD between the sets of samples 




Close-by samples have a high (
We then compute the empirical MMD as:



Note that if 

2. MMD in theory
We now want to show that, in its essence, the MMD with RBF kernel computes the dissimilarity between all moments of the two distributions:

To connect this with the empirical MMD formula above, we need to take two mental steps:
- Unpack the RBF kernel
- Unpack the empirical MMD formula
2.1. Step 1: Unpack the RBF kernel
We first rewrite the RBF kernel in a more convenient form:

(To keep things simple, we have considered unidimensional samples, i.e., 
Then, we develop the cross-product term via Taylor expansion:


We can then rewrite the kernel as the scalar product of two infinite-dimensional vectors (“features”) 


where:


Before we move on to unpack the MMD formula, let’s make a couple of seemingly convoluted but important observations.
Observation 1. Computing the RBF kernel
- Project the samples
- Compute the scalar product
between the two features
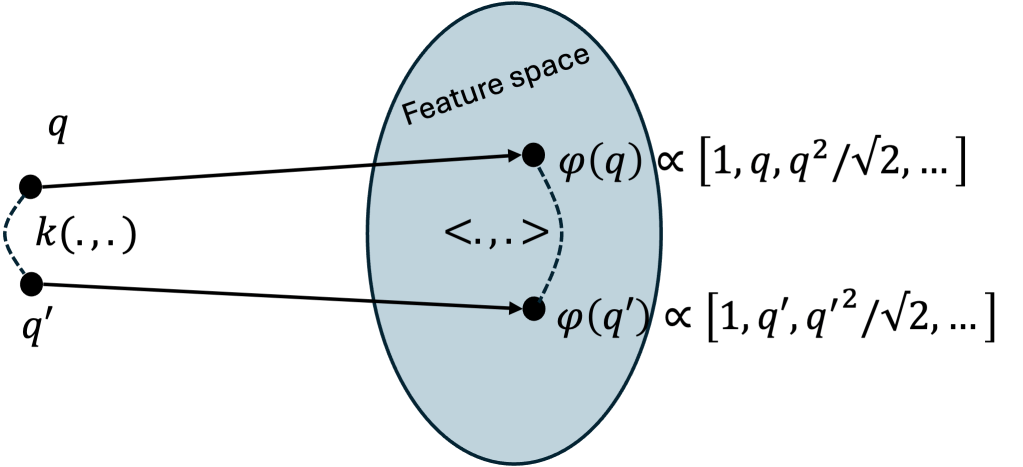
Observation 2. Define the (infinite-dimensional!) vector 

Then,

As a consequence, MMD compares the variance, the skewness, the kurtosis, etc. of two distributions simultaneously. Let’s show this in detail below.
2.2. Step 2: Unpack the MMD formula
We are now ready to dissect the MMD formula to show that it computes the dissimilarity between all moments of the two distributions.
We plug the definition (2) of the kernel as the inner product of features into the empirical MMD formula (1) to obtain:


By exploiting the linearity property of the inner product, we can rewrite the MMD formula as:



Et voilà ! The empirical MMD can be rewritten as the squared distance between the mean features of
References
[1] Gretton, A., Borgwardt, K. M., Rasch, M. J., Scholkopf, B., Smola, A. (2012). A kernel two-sample test. The journal of machine learning research, 13(1), 723-773.

Leave a comment