Proximal Policy Optimization (PPO) algorithm is arguably the default choice in modern reinforcement learning (RL) libraries.
In this post we understand how to derive PPO from first principles. First, we brush up our memory on the underlying Markov Decision Process (MDP) model.
1. Preliminaries on Markov Decision Process (MDP)
In an MDP, an agent (say, a robot navigating a maze) interacts with an environment that evolves over time. If at step 


- the agent receives a reward
(the robot’s distance from the goal);
- the environment transitions to state
at the next step
, with probability
(the robot’s new position).
Note that the Markov property is assumed: the knowledge of the current state is sufficient to evaluate the transition probability to the next state.
The agent’s behavior is described by policy 







where the notation 
The agent optimizes its strategy 

1.1. Advantage function
To improve the performance of a policy, it is important to learn whether a deviation from the base policy brings any benefit. This is formalized by the advantage function. We call 

where 

1.2. Policy parametrization
When the number of states is large, we typically avoid defining the agent’s strategy in each state individually. Instead, it is convenient to define the policy 

2. Performance gain
PPO is an algorithm that iteratively improves the performance of an initial policy. It is then useful to evaluate the performance gain 


As shown in [1], [2], 

The right-hand side of (4) reads as follows:
Follow the new strategy 


Visually:
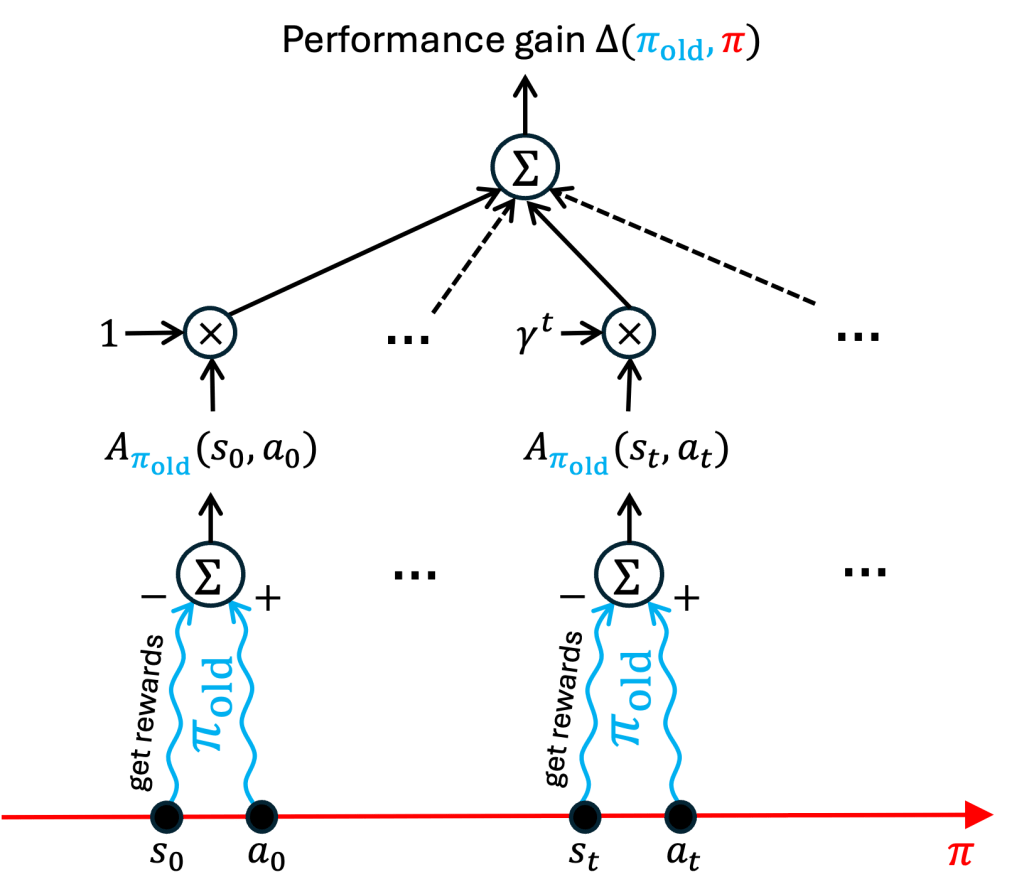
2.1. A more explicit formula for
It is convenient to formulate 

We then exchange the sum order:


where 

Notice that in expression (5), the effect of policy
3. How to make
To improve upon our baseline policy

Idea 1: Maximizing
Idea 2: Policy improvement. Let us look back at expression (5). The policy 


In other words, to obtain 

Such approach generalizes the classic policy improvement algorithm, that maximizes the advantage function in each state:

However, when the number of states is large, such method presents several issues:
- i) Enumerating all states may be infeasible in the first place
- ii) The advantage function
is not known precisely; thus,
may take wrong decisions resulting in
- ii) When the policy is a parametric function, its degrees of freedom are reduced; hence, optimizing the policy independently in each state becomes impossible.

Idea 3: Maximize a lower bound PPO, as well its ancestor TRPO, overcome the limitations above by maximizing a convenient lower bound for
4. A lower bound for the performance gain
We derive a lower bound for the performance gain
Step 1: Approximating
- (inner sum) the expected action advantage
in each state
- (outer sum) the weighted average of the inner terms with respect to the state visitation frequency

It turns out that when a policy 



Step 2: Quantify the “closeness” between strategies 

Observe that 


Step 3: Deriving the lower bound for

where 
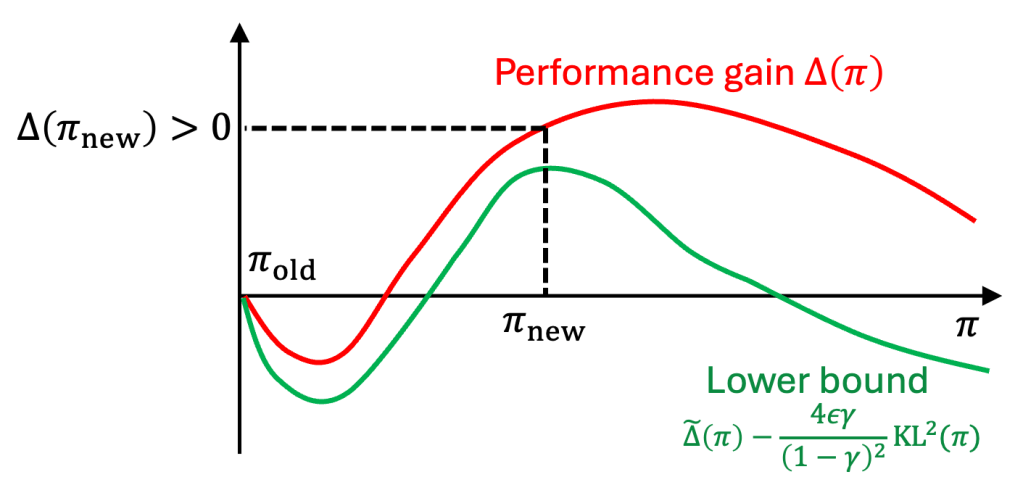
5. TRPO: Maximize the lower bound
Trust Region Policy Optimization (TRPO) [2], PPO’s direct ancestor, maximizes the performance gain lower bound (12):

In this case, we strive to jointly
- Select advantageous actions to increase the approximate gain
- Remain close to the base policy
Observe that, as a side-product, the latter point is of practical importance to ensure stability.
As promised, 
5.1. Towards practice (1): Turn penalty into constraint
In practice, the coefficient penalizing the


5.2. Towards practice (2): Estimating 
Computing the analytical expression of
Estimating
- Express it as an expectation with respect to the base policy
- Compute empirical averages across multiple trajectories obtained by following
In detail, we first multiply and divide each term of the inner sum of expression (10) by 

Then, we can estimate 


Visually:

5.3. Towards practice (3): Estimating the advantage function
In this post we do not discuss how to estimate the advantage function. For this, the reader is encouraged to consult the excellent reference [4].
5.4. Addressing the issues of policy improvement
As promised, TRPO solves (or at least, mitigates) the issues with policy improvement (PI):
- i) Unlike PI, TRPO does not need to enumerate all states;
- ii) TRPO is more robust to uncertainties in the advantage function than PI, since TRPO maximizes an aggregate advantage function rather than each individual advantage term
;
- iii) For the same reason, TRPO is more suitable than PI for parametric policies, for which actions cannot be optimized independently in each state.
5.5. All that glitters is not (yet) gold
Finding the constrained TRPO policy 
6. Proximal Policy Optimization (PPO)
PPO gets away with the hard-to-handle TRPO’s constraint on the KL divergence by re-incorporating it in the objective function in a friendly way, i.e., solvable by gradient descent. To understand how, we follow 4 steps.
Step 1. Let us first recall informally TRPO’s goal:
Maximize the approximate performance gain
Step 2. What goes wrong when we omit the constraint on

The optimal policy would tend to assign high probability to actions with a large ratio “advantage” to “probability of being chosen by the old policy”:

Visually:
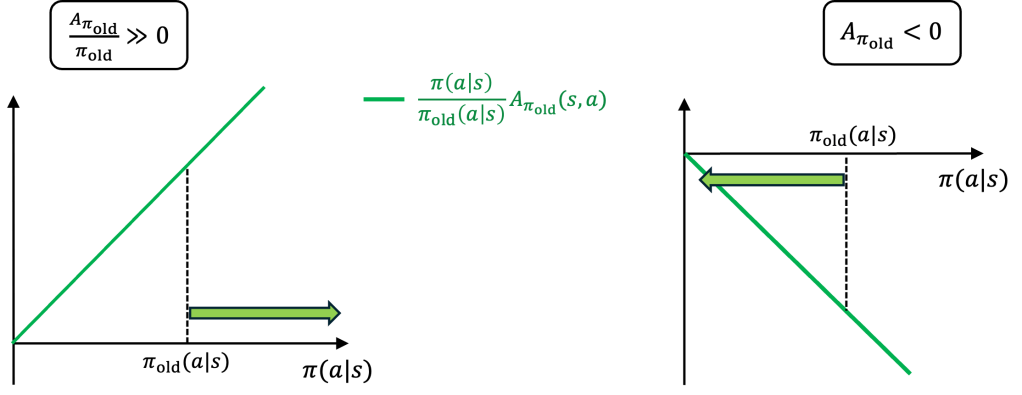
Thus, actions that were chosen very infrequently under
On the other hand, actions with an even slightly negative advantage would be completely ruled out. Again, this is not wise, due to the advantage estimation inaccuracies.
Step 3. PPO prevents the issues above by artificially limiting the reward for choosing policies that deviate too far from the old policy
In details, PPO maximizes a new objective function

where the individual terms 

The equation above is best understood via an illustration:
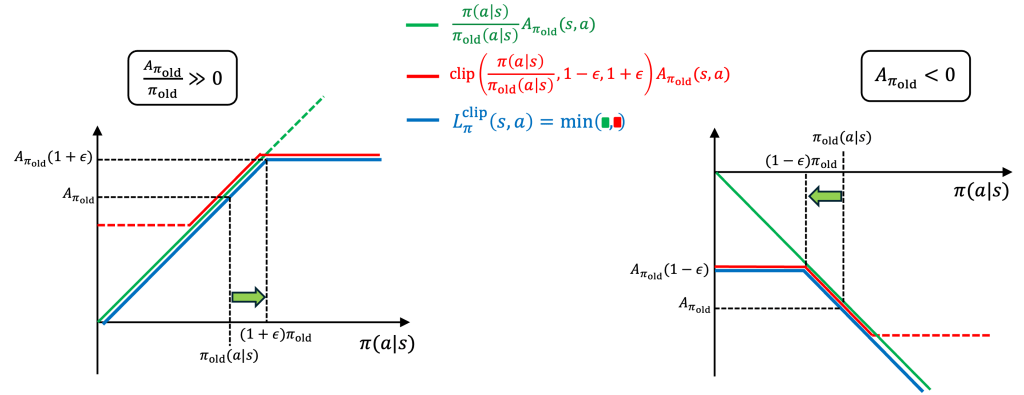
This shows that even when action 

Step 4. PPO can now be solved via gradient descent. The policy 

6.1. PPO’s main steps
To sum up, here are the main steps of PPO algorithm:
- a) Start from an arbitrary randomized policy
- b) Repeat until convergence:
- 1) Run policy
- 2) Estimate the advantage function
, for all steps
- 3) Solve via gradient-based methods:
- 4) Replace
- 1) Run policy


![\displaystyle \theta^* = \mathrm{arg\,max}_{\theta} \, \widehat{\mathbb{E}}_{\{s_t,a_t\}_t \sim \pi_{\mathrm{old}}} \left[ \sum_{t\ge 0} \gamma^t L^{\mathrm{clip}}_{\pi_{\theta}}(s_t, a_t) \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctheta%5E%2A+%3D+%5Cmathrm%7Barg%5C%2Cmax%7D_%7B%5Ctheta%7D+%5C%2C+%5Cwidehat%7B%5Cmathbb%7BE%7D%7D_%7B%5C%7Bs_t%2Ca_t%5C%7D_t+%5Csim+%5Cpi_%7B%5Cmathrm%7Bold%7D%7D%7D+%5Cleft%5B+%5Csum_%7Bt%5Cge+0%7D+%5Cgamma%5Et+L%5E%7B%5Cmathrm%7Bclip%7D%7D_%7B%5Cpi_%7B%5Ctheta%7D%7D%28s_t%2C+a_t%29+%5Cright%5D+&bg=ffffff&fg=000000&s=1&c=20201002)

References
[1] Kakade, S., Langford, J. (2002, July). Approximately optimal approximate reinforcement learning. In Proceedings of the nineteenth international conference on machine learning (pp. 267-274).
[2] Schulman, J., Levine, S., Abbeel, P., Jordan, M., Moritz, P. (2015, June). Trust region policy optimization. In International conference on machine learning (pp. 1889-1897). PMLR.
[3] Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
[4] Schulman, J., Moritz, P., Levine, S., Jordan, M., Abbeel, P. (2015). High-Dimensional Continuous Control Using Generalized Advantage Estimation arXiv:1506.02438.

Leave a comment