We consider constrained optimization problems of the kind:

where the feasibility region 


where 






where 




In this post we will study necessary conditions that function 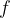

1. Basic principle and three open questions
In simple words, KKT conditions state that in a neighborhood of any optimal
- What a (feasible) neighborhood looks like?
- How to know whether
- How to restate the optimality condition in a form that is actually computable, rather than merely as an abstract definition?
Next we will answer all three questions using geometric insights. Finally, we will also provide an example where KKT conditions actually help us solve the optimization problem.
2. Non-increasing property
Let us place ourselves at the optimum 
Along the feasible direction 
![{\nabla f(\mathbf{x}^*)=[\frac{df}{dx_1}(\mathbf{x}^*),\dots,\frac{df}{dx_N}(\mathbf{x}^*)]}](https://s0.wp.com/latex.php?latex=%7B%5Cnabla+f%28%5Cmathbf%7Bx%7D%5E%2A%29%3D%5B%5Cfrac%7Bdf%7D%7Bdx_1%7D%28%5Cmathbf%7Bx%7D%5E%2A%29%2C%5Cdots%2C%5Cfrac%7Bdf%7D%7Bdx_N%7D%28%5Cmathbf%7Bx%7D%5E%2A%29%5D%7D&bg=ffffff&fg=000000&s=1&c=20201002)


Condition (3) is a valid necessary optimality condition, although still quite primitive, since 


which is the classic first-order optimality condition for unconstrained optimization.
3. Feasible directions
We next refine the optimality condition (3) by characterizing the set of feasible directions
As it turns out,

This stems from the convexity property of the feasibility region

We can now make the optimality condition (3) more explicit by rewriting it as:

Although we’ve made headway, there is still something unsatisfying about condition (5): validating the relationship across all feasible points feels like too daunting of a task. We will take care of this in the next section.
4. KKT conditions via normal cones
Condition (5) states that, in order for 



In the hope of further refining condition (5), we are then interested in characterizing
We build up to its general definition via examples of increasing complexity.
(Temporarily) discard equality constraints 

The optimum is inside 
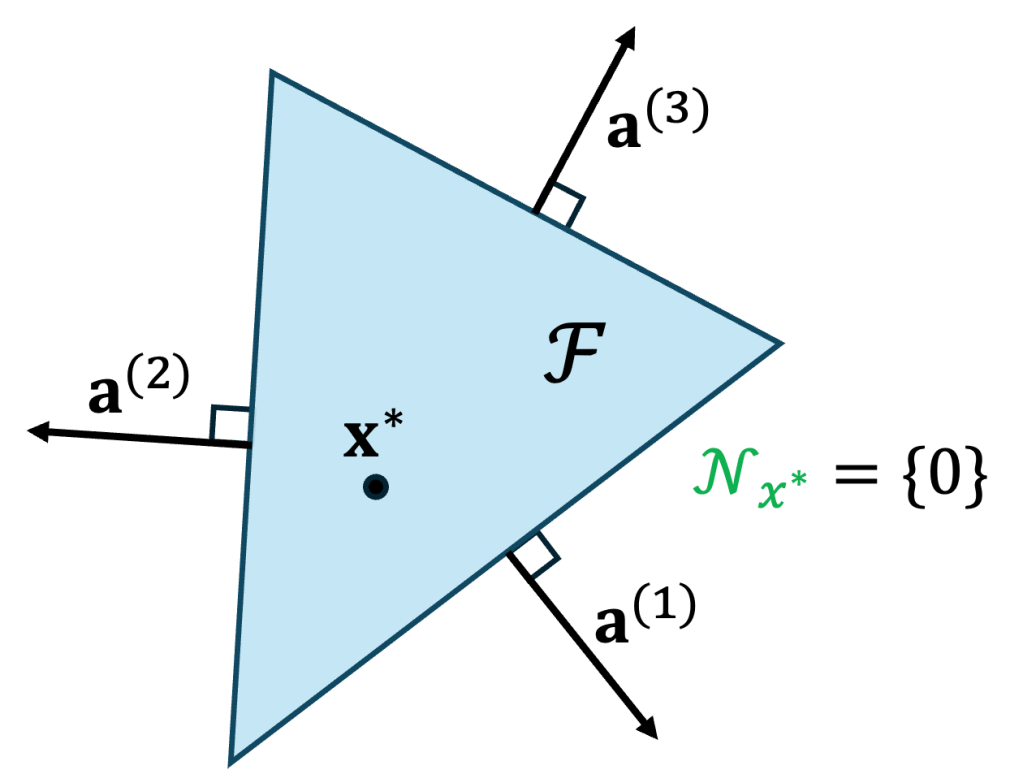
One constraint is tight. Next, we suppose that 
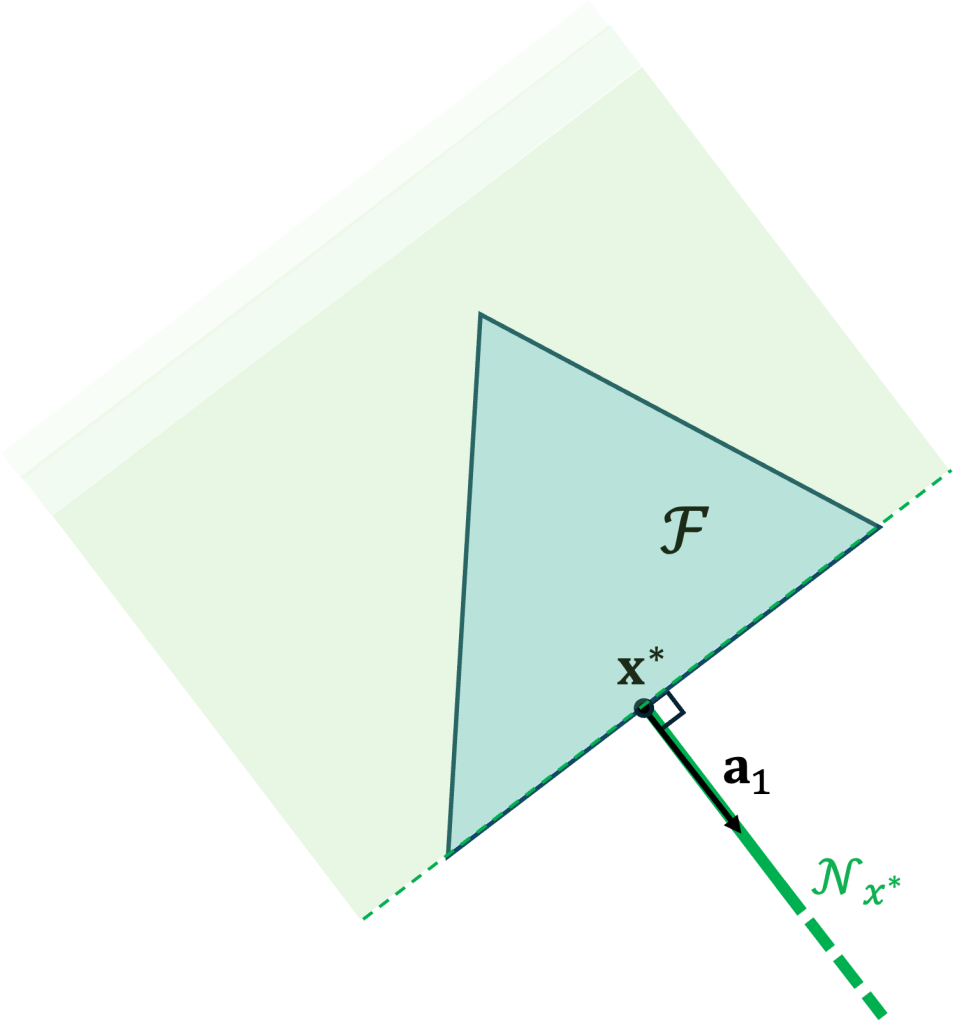
Observe that the green shaded region denotes the set of vectors that are anti-aligned with
Two constraints are tight. When two constraints are tight—say the first two—instead of just one, the feasibility region 

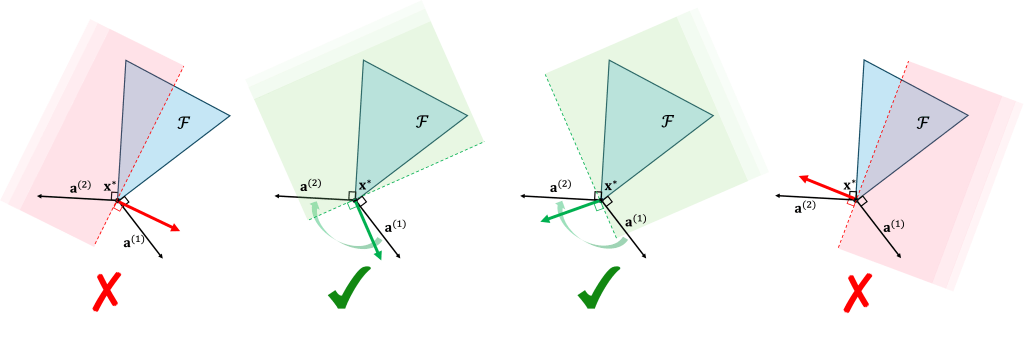
More formally,

where 
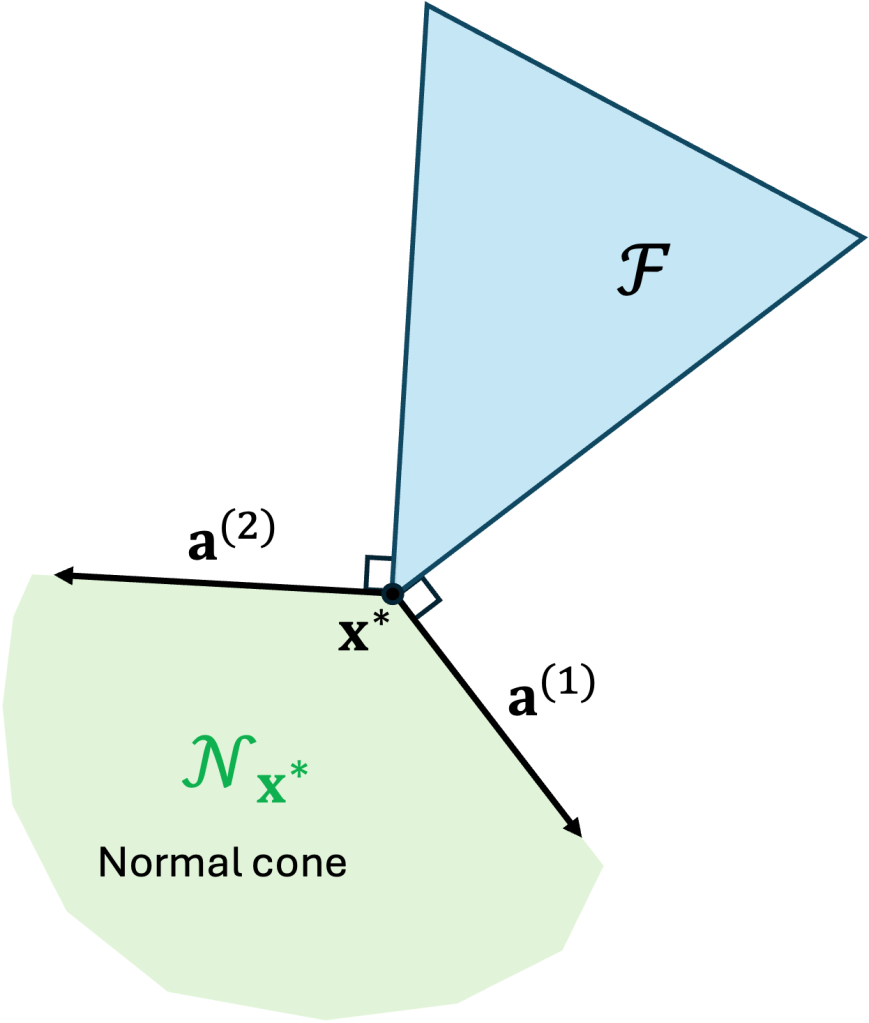
Multiple constraints are tight. The same intuitions we just gained with two tight constraints also apply when dealing with multiple tight constraints. To give a final polish to our expression of 


where (9) is the complementary slackness condition, claiming that
- if the
, then
, thus
does not contribute to
- if the
, then
, thus
Bringing back equality constraint. We now what we have learnt so far to the initial case with inequality constraints 
Let us start simple: in the presence of just one equality constraint 


Observe that unlike the inequality case, where multipliers are nonegative, the normal cone is formed by scaling
To make this statement more formal, we first rewrite every equality constraint 


Then, we assign nonnegative Lagrangian multipliers 


It is convenient to assign just one multiplier 

We also observe that the complementary slackness condition (9) still holds the same, since equality constraitns are tight by definition.
Putting all together: KKT conditions. After quite some work, we are finally ready to provide the polished version of KKT optimality conditions.
If 




5. A formal proof
For those who want to go deeper, below we prove that the normal cone at point
Theorem 1 Let
be the feasibility region with inequalities only and call
the set of constraints being tight at point
the cone spanned by
coincides with the normal cone
.
Proof: We first prove that 





where the equality in (12) comes from the definition of 



Next, we prove that 



By the hyperplane separation theorem, there exists a vector


We try with 



We distinguish two cases:
- Case
. Here,
, hence it suffices to choose
- Case
. Here,
, so it must hold that
for
for all
. Since
, then
Hencefor some
for all
for any
and with
, or equivalently:
By letting, we obtain
, as wished!



Hence, we showed that, for

Thus,

6. Can KKT help us solve the optimization problem?
The answer is yes, although often not in a direct way. Instead, the KKT conditions give us clues about what the optimal solution may look like, and a bit of creativity is required to complete the process. An insightful example is the following:



that often arises in wireless signal processing in the context of power allocation, where 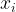

![{\nabla f(\mathbf{x})=[\frac{1}{n_i+x_i}]_{i=1,\dots,N}}](https://s0.wp.com/latex.php?latex=%7B%5Cnabla+f%28%5Cmathbf%7Bx%7D%29%3D%5B%5Cfrac%7B1%7D%7Bn_i%2Bx_i%7D%5D_%7Bi%3D1%2C%5Cdots%2CN%7D%7D&bg=ffffff&fg=000000&s=1&c=20201002)
![{\mathbf{c}^{(1)}=[1,\dots,1]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbf%7Bc%7D%5E%7B%281%29%7D%3D%5B1%2C%5Cdots%2C1%5D%7D&bg=ffffff&fg=000000&s=1&c=20201002)



Then, 



where we highlighted the fact that 




Since 

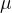
7. Extending to non-linear constraints
When constraints are non-linear and of the kind 




References
[1] W. Karush (1939). Minima of Functions of Several Variables with Inequalities as Side Constraints (M.Sc. thesis). Dept. of Mathematics, Univ. of Chicago, Chicago, Illinois.
[2] Kuhn, H. W.; Tucker, A. W. (1951). Nonlinear programming. Proceedings of 2nd Berkeley Symposium. Berkeley: University of California Press. pp. 481–492. MR 0047303
[3] Blogpost video version: https://www.youtube.com/watch?v=h8KBlVIpA1A&t=1293s

Leave a reply to Lorenzo Maggi Cancel reply