In this post we review different methods to compute prediction intervals, containing the next (unknown) observation with high probability and being at the heart of Conformal Prediction (CP). We will highlight that each method is characterized by a different and non-trivial trade-off between computational complexity, coverage properties and the size of the prediction interval.
Scenario. We are given a dataset of pairs 
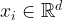



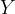
Given any new observation 




where the probability is marginalized over all possible datasets 

Conformal prediction (CP) addresses our need. Next we present four different procedures to achieve coverage properties similar to (1). such procedures all take a single point-wise predictor (say, least-square) and wrap the predictor’s output around a set that contains the new output with high probability.
1. Preliminaries
Let us first conveniently define the following notation.
We denote by 




Given a set of 


If 



We conclude this section with an important result [1] that justifies the coverage properties of two CP methods.
Theorem 1 Suppose that random variables
are exchangeable. Then,
where the second inequality holds if variables are almost surely distinct.
We recall that random variables are exchangeable if their distribution is invariant to a permutations of their order. Observe that i.i.d. variables are exchangeable, although the converse does not hold. Hence, the result above is also valid under the more common i.i.d. assumption.

2. Split conformal prediction
Split CP is probably the simplest method achieving finite-sample coverage properties.
Procedure.
- Randomly split the dataset
and calibration dataset
- Train a predictor
on the training set
- Compute the empirical quantile of the residuals on the calibration samples:
- Receive the new input
- Return the prediction interval:



![\displaystyle \mathcal C^{\mathrm{split}}(x_{n+1}) = \left[ f_{\mathcal D^t}(x_{n+1}) - \widehat{q}; \, f_{\mathcal D^t}(x_{n+1}) + \widehat{q} \right] \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal+C%5E%7B%5Cmathrm%7Bsplit%7D%7D%28x_%7Bn%2B1%7D%29+%3D+%5Cleft%5B+f_%7B%5Cmathcal+D%5Et%7D%28x_%7Bn%2B1%7D%29+-+%5Cwidehat%7Bq%7D%3B+%5C%2C+f_%7B%5Cmathcal+D%5Et%7D%28x_%7Bn%2B1%7D%29+%2B+%5Cwidehat%7Bq%7D+%5Cright%5D+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=1&c=20201002)
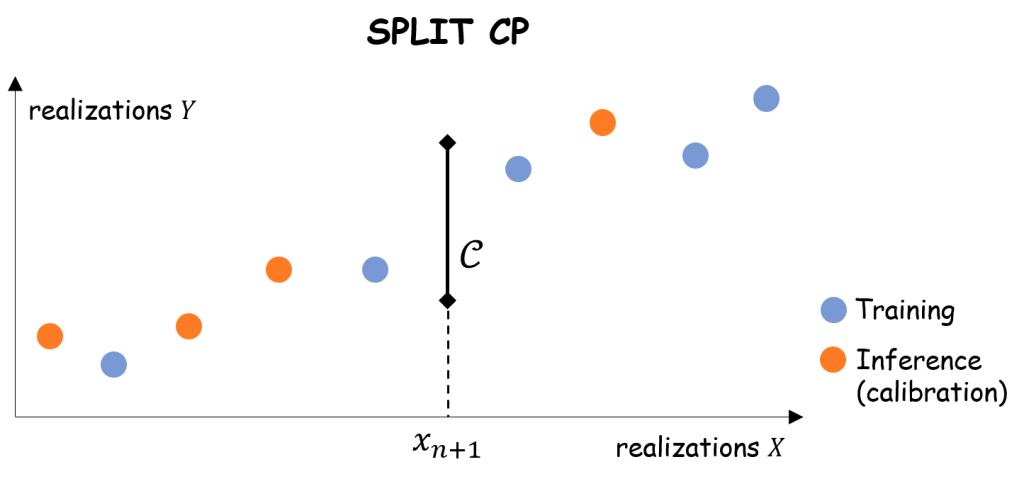
The coverage property of split CP directly stems from Theorem 1.
Corollary 2 If the residuals on the calibration samples and the new sample
where the second inequality holds if the residuals are almost surely distinct.

Pro’s: Split CP has low computational complexity as it only requires to train the predictor 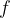
Con’s: Split CP may produce a large prediction interval, especially if the dataset is small. In fact, if the training samples are few then the resulting predictor is poor, and its residuals on the calibration samples are large.
3. Full conformal prediction
We first define 




Procedure. (Ideal but impractical)
- Receive the new input
- Compute the prediction set:

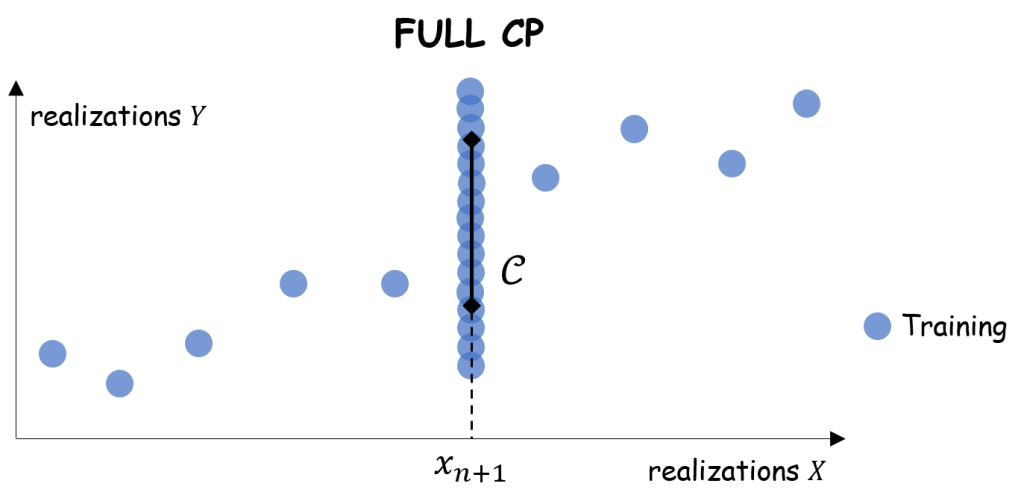
A coverage guarantee similar to the one for split CP, still stemming directly from Theorem 1, is achievable for full CP.
Corollary 3 If the residuals on training samples and the new sample
where the second inequality holds if residuals are almost surely distinct.

Remark. For the residual exchangeability hypothesis to hold, it is not enough to assume that the samples 
Pro’s: Full CP is data efficient, since it trains the regressor on all available historical samples.
Con’s: Full CP is impractical, since it ideally requires infinite computational complexity: the regressor used to decide whether 

To alleviate the computational complexity issue, one can simply evaluate whether a point
Procedure. (Practical but approximated)
- Define a grid
- Receive the new input
- Initialize
and
.
For:
- Train the regressor
- Compute the empirical quantile of residuals
- If
then add
. Otherwise, add
.
- Train the regressor

Finally, to obtain a compact prediction set, one can use the nearest neighbor rule: given ![{y[0],\dots,y[k]}](https://s0.wp.com/latex.php?latex=%7By%5B0%5D%2C%5Cdots%2Cy%5Bk%5D%7D&bg=ffffff&fg=000000&s=1&c=20201002)
4. Jackknife+
The intuition behind Jackknife+ [2] is the following. Consider the regressor 
(that we can compute)
(that we do not know)
are also exchangeable. Hence, we can exploit the former to learn the distribution of residuals of the new point with respect to the regressor 
Procedure.
- For
:
- i) train the regressor
- ii) compute the residual
- i) train the regressor
- Receive the new input
- Compute the lower quantile:
- Compute the upper quantile:
- Return the prediction interval:




![\displaystyle \mathcal C^{j+}(x_{n+1})= \left[\widehat{q}^- ; \, \widehat{q}^+ \right] \ \ \ \ \ (9)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal+C%5E%7Bj%2B%7D%28x_%7Bn%2B1%7D%29%3D+%5Cleft%5B%5Cwidehat%7Bq%7D%5E-+%3B+%5C%2C+%5Cwidehat%7Bq%7D%5E%2B+%5Cright%5D+%5C+%5C+%5C+%5C+%5C+%289%29&bg=ffffff&fg=000000&s=1&c=20201002)

Theorem 4 If the regressor
are exchangeable, then

Pro’s: Jackknife+ is data efficient as the regressor is trained on the whole dataset (except for a single point). Thanks to this, the produced prediction interval is generally shorter than for split CP, especially if the dataset
Con’s: Jackknife+ has a non-negligible computational complexity, especially if the dataset is large. In fact, it retrains the regressor
5. Cross-Validation+
To alleviate the complexity issue of Jackknife+, Cross-Validation+ (CV+) [2] first split the historical dataset 





![\displaystyle \qquad \qquad \qquad q_{\lceil (1-\alpha)(n+1) \rceil}\big\{f_{\mathcal D\setminus \mathcal D_{k(i)}}(x_{n+1}) + R_i^{\mathrm{CV+}} \big\}_{i\le n} \big] \ \ \ \ \ (11)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cqquad+%5Cqquad+%5Cqquad+q_%7B%5Clceil+%281-%5Calpha%29%28n%2B1%29+%5Crceil%7D%5Cbig%5C%7Bf_%7B%5Cmathcal+D%5Csetminus+%5Cmathcal+D_%7Bk%28i%29%7D%7D%28x_%7Bn%2B1%7D%29+%2B+R_i%5E%7B%5Cmathrm%7BCV%2B%7D%7D+%5Cbig%5C%7D_%7Bi%5Cle+n%7D+%5Cbig%5D+%5C+%5C+%5C+%5C+%5C+%2811%29&bg=ffffff&fg=000000&s=1&c=20201002)
where 


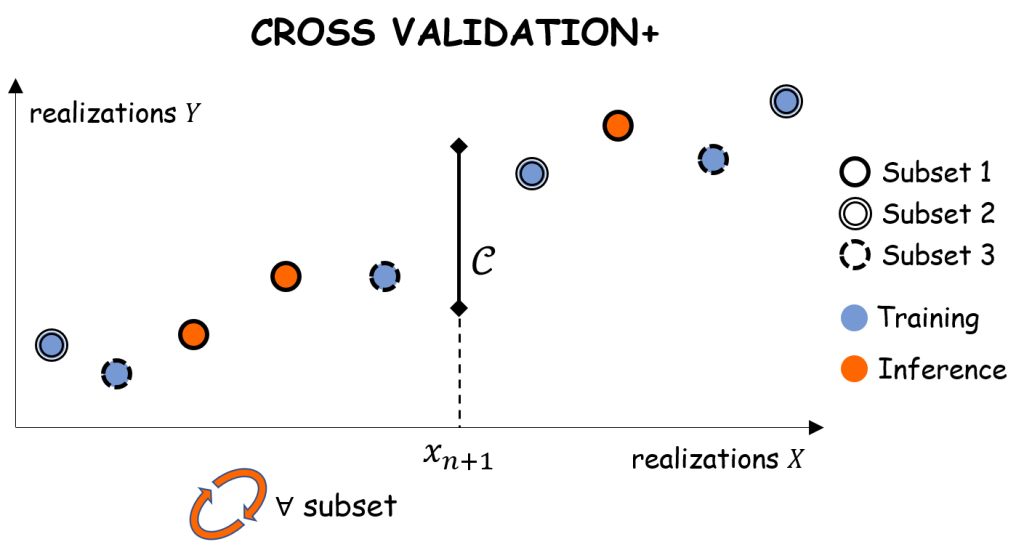
Observe that the Cross-Validation+ procedure boils down to Jackknife+ when 
Theorem 5 The Cross-Validation+ prediction interval satisfies:

When 
Pro’s: Cross-Validation+ is characterized by a lighter computational complexity than Jackknife+, especially if the number
Con’s: Cross-Validation+ has worse coverage guarantees than Jackknife+, especially if the number
6. Other important CP methods
Amongst the other main methods for conformal prediction present in the literature, we mention:
- Cross-Validation-minmax and Jackknife+-minmax [2]
- Conformalized quantile regression (CQR) [4], already covered in a previous [post]
- Jackknife+-after-bootstrap [5]
- Ensemble batch prediction intervals (EnbPI) [6]
References
[1] Angelopoulos, Anastasios N., and Stephen Bates. Conformal prediction: A gentle introduction. Foundations and Trends in Machine Learning 16.4 (2023): 494-591.
[2] Barber, R. F., Candes, E. J., Ramdas, A., and Tibshirani, R. J. Predictive inference with the jackknife+. The Annals of Statistics, 49(1):486–507, 2021.
[3] Vovk, Vladimir, Alexander Gammerman, and Glenn Shafer. Algorithmic Learning in a Random World. Springer Nature, 2022.
[4] Romano, Yaniv, Evan Patterson, and Emmanuel Candes. Conformalized quantile regression. Advances in neural information processing systems 32 (2019)
[5] Byol Kim, Chen Xu, and Rina Foygel Barber. Predictive Inference Is Free with the Jackknife+-after-Bootstrap. 34th Conference on Neural Information Processing Systems (NeurIPS 2020)
[6] Xu, Chen et Xie, Yao. Conformal prediction interval for dynamic time-series. In : International Conference on Machine Learning. PMLR, 2021. p. 11559-11569.
[7] Manokhin, V. Awesome conformal prediction [Github repo].
[8] Taquet, V., Blot, V., Morzadec, T., Lacombe, L., Brunel, N. (2022). MAPIE: an open-source library for distribution-free uncertainty quantification. arXiv preprint arXiv:2207.12274. [Python library]

Leave a comment