Pimp quantile regression with strong coverage guarantees
Suppose that we are given a historical dataset containing 

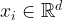



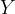
As a running example, let us consider the following dataset:
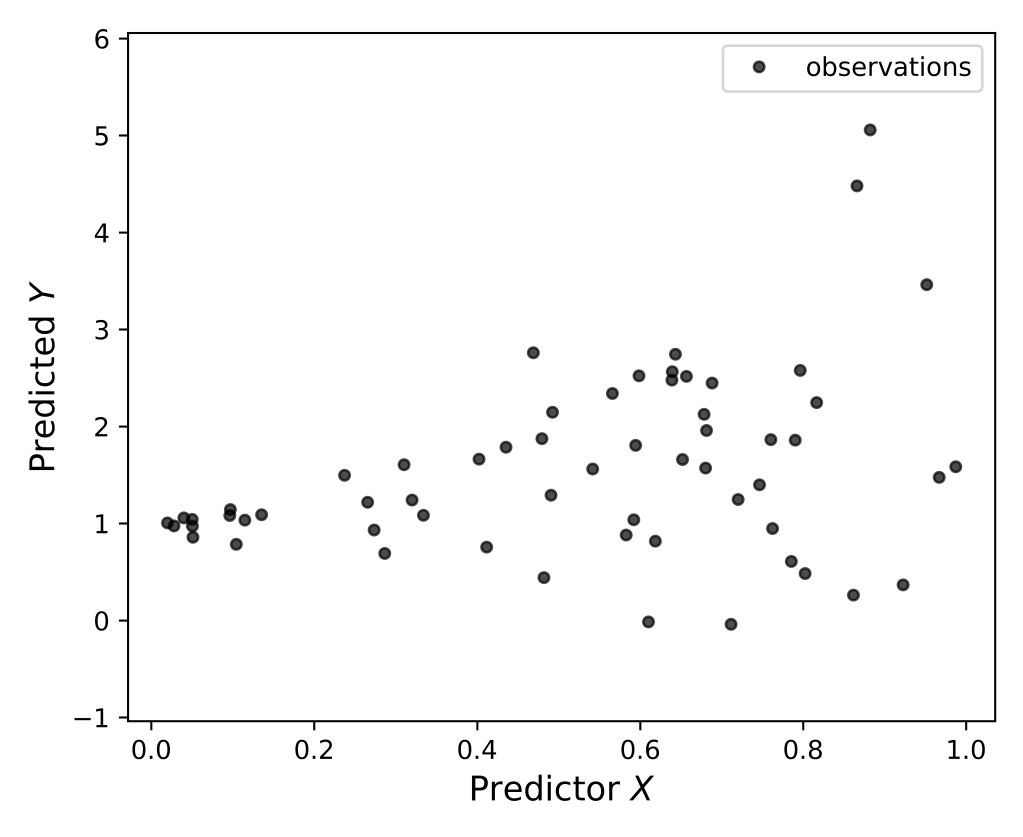
Our goal #1 is to estimate the trend of variable 



Our goal #2 is that the length of the prediction interval 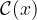



In this post we show how to achieve goals #1 and #2 via conformal quantile regression (CQR), first proposed by Y. Romano, E. Patterson and E. Candes in [1], which applies conformal prediction (CP) to quantile regression (QR) via a powerful and surprisingly simple-to-implement procedure.
First, let us investigate how QR and “vanilla” CP alone would address our problem, and how each fails to jointly achieve our goals.
1. Via quantile regression (QR)
As explained in a previous post [link], the 
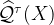
![{\mathcal Q^{\tau}[Y|X]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal+Q%5E%7B%5Ctau%7D%5BY%7CX%5D%7D&bg=ffffff&fg=000000&s=1&c=20201002)
Then, a natural attempt to build a prediction interval with coverage,
- Train a low-quantile regressor
on all
- Train a high-quantile regressor
on all
- Approximate the coverage function as
![\displaystyle \mathcal C^{\mathrm{QR}}(x) = \left[\widehat{\mathcal Q}^{\frac{\alpha}{2}}(x); \, \widehat{\mathcal Q}^{1-\frac{\alpha}{2}}(x)\right], \quad \forall\, x \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal+C%5E%7B%5Cmathrm%7BQR%7D%7D%28x%29+%3D+%5Cleft%5B%5Cwidehat%7B%5Cmathcal+Q%7D%5E%7B%5Cfrac%7B%5Calpha%7D%7B2%7D%7D%28x%29%3B+%5C%2C+%5Cwidehat%7B%5Cmathcal+Q%7D%5E%7B1-%5Cfrac%7B%5Calpha%7D%7B2%7D%7D%28x%29%5Cright%5D%2C+%5Cquad+%5Cforall%5C%2C+x+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=1&c=20201002)
If we apply this procedure to our initial dataset with 


Pro’s: Goal #2 is achieved: 
Con’s: Goal #1 is not not achieved. In fact, it holds only asymptotically, as the number of training samples
2. Via vanilla conformal prediction (CP)
We discussed about CP in a previous post [link].
The “vanilla” CP procedure applied to our problem goes as follows:
- Randomly split the
and a calibration set
- Train a least-square regressor
on the training set
- Evaluate the performance of
- Compute the empirical
-th quantile of the scores:
- Output the coverage function:
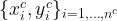

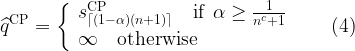
![\displaystyle \mathcal{C}^{\mathrm{CP}}(x) = \left[\widehat{\mathcal L}(x)-\widehat{q}^{\mathrm{CP}}; \, \widehat{\mathcal L}(x)+\widehat{q}^{\mathrm{CP}} \right], \quad \forall\, x\in\mathcal{X}. \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BC%7D%5E%7B%5Cmathrm%7BCP%7D%7D%28x%29+%3D+%5Cleft%5B%5Cwidehat%7B%5Cmathcal+L%7D%28x%29-%5Cwidehat%7Bq%7D%5E%7B%5Cmathrm%7BCP%7D%7D%3B+%5C%2C+%5Cwidehat%7B%5Cmathcal+L%7D%28x%29%2B%5Cwidehat%7Bq%7D%5E%7B%5Cmathrm%7BCP%7D%7D+%5Cright%5D%2C+%5Cquad+%5Cforall%5C%2C+x%5Cin%5Cmathcal%7BX%7D.+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=1&c=20201002)
If applied to our initial dataset with a linear least-square regressor using polynomial features of order 2, vanilla CP produces the following result:

Pro’s: Goal #1 is achieved: in fact, under some technical assumptions (see Theorem 2, of our previous post [link]), it holds that, for any new pair of realizations
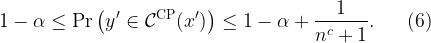
Con’s: Goal #2 is not achieved: the length of the prediction interval is constant across all values of
3. Conformalized quantile regression (CQR)
The question arises naturally: Can we take the best of the worlds, QR and CP, and jointly achieve goals #1 and #2?
The answer is yes, via Conformalized Quantile Regression (CQR) [1]. CQR is a direct application of the split CP paradigm to QR, that tweaks the empirical coverage interval 
CQR Procedure.
- Randomly split the
- Train a lower quantile regressor
training samples
- Train an upper quantile regressor
- Computing on the calibration points
the scores:
- Compute the empirical
- Output the coverage interval:


![\displaystyle \mathcal{C}^{\mathrm{CQR}}(x) = \left[\widehat{\mathcal Q}^{\frac{\alpha}{2}}(x) - \widehat{q}^{\mathrm{CQR}}; \, \widehat{\mathcal Q}^{1-\frac{\alpha}{2}}(x) + \widehat{q}^{\mathrm{CQR}}\right], \quad \forall\, x. \ \ \ \ \ (9)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BC%7D%5E%7B%5Cmathrm%7BCQR%7D%7D%28x%29+%3D+%5Cleft%5B%5Cwidehat%7B%5Cmathcal+Q%7D%5E%7B%5Cfrac%7B%5Calpha%7D%7B2%7D%7D%28x%29+-+%5Cwidehat%7Bq%7D%5E%7B%5Cmathrm%7BCQR%7D%7D%3B+%5C%2C+%5Cwidehat%7B%5Cmathcal+Q%7D%5E%7B1-%5Cfrac%7B%5Calpha%7D%7B2%7D%7D%28x%29+%2B+%5Cwidehat%7Bq%7D%5E%7B%5Cmathrm%7BCQR%7D%7D%5Cright%5D%2C+%5Cquad+%5Cforall%5C%2C+x.+%5C+%5C+%5C+%5C+%5C+%289%29&bg=ffffff&fg=000000&s=1&c=20201002)

To gather more intuitions, it is instructive to consider the following 3 cases:
- Case a): the interval
built via QR regression only is already conformal. In this case, a portion
land within
(hence, their score
is negative) while the remaining
fall outside
.
- Case b):
is positive, hence the resulting interval
is larger than the non-conformal
- Case c)

If applied to our initial dataset, CQR provides the following result.
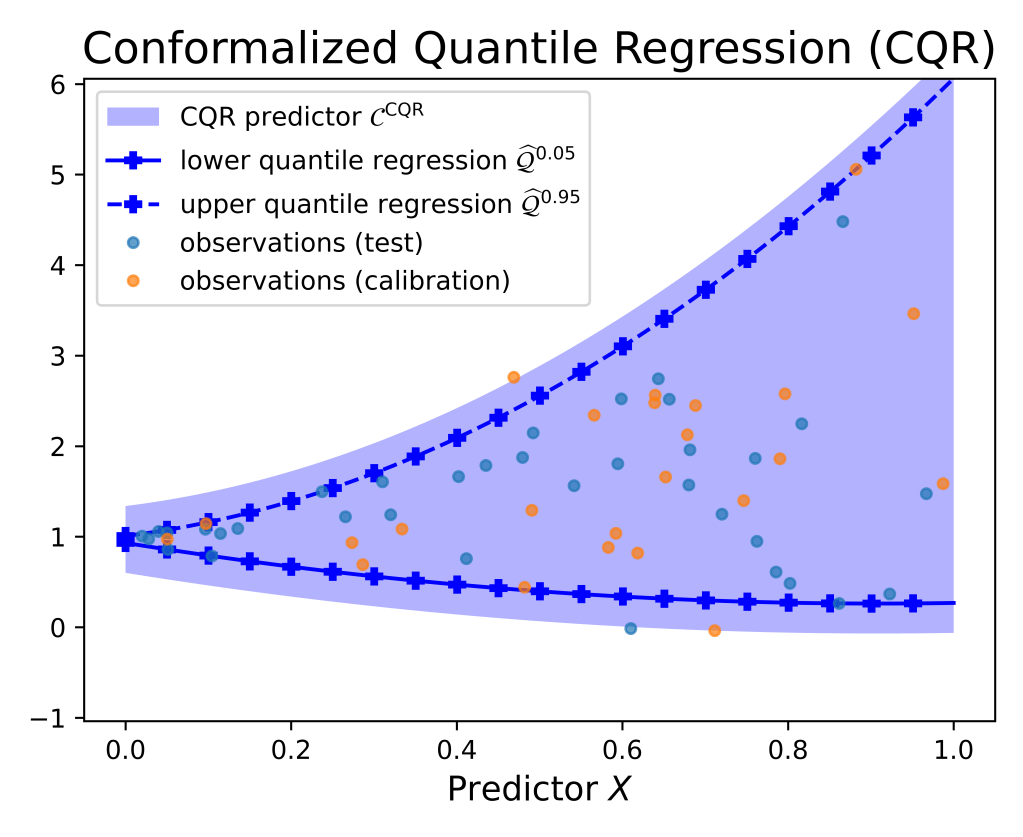
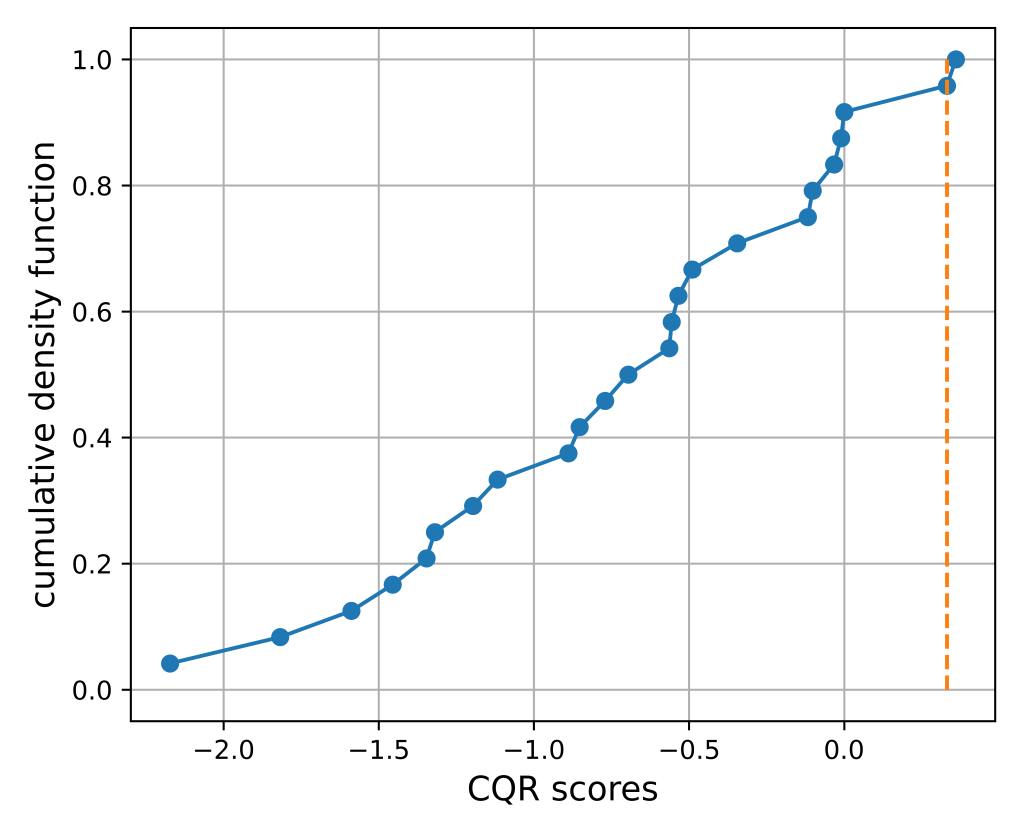
Note that, in this case, the QR interval under-covers calibration samples. In fact, the calibration score distribution is as follows:
Goal #2 is achieved by CQR, since CQR merely displaces the levels set by the QR regression by a constant offset. We conclude by proving formally that the CQR procedure achieves goal #1 as well, on the coverage probability.
Theorem 1 Let
. Suppose that the scores
are exchangeable random variables. Then, the prediction interval
satisfies:
where the second inequality holds if the scores are almost surely distinct.
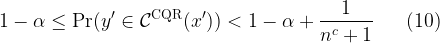
Proof: The event 

By rearranging the terms of (11), we obtain the equivalent expression:

It stems that 

3.1. Discussion: Marginal vs Conditional coverage
It is important to understand that the coverage probability 


On the other hand, the coverage probability does not hold marginally, i.e., in point-wise fashion:

In other words, if we fix 

This is illustrated below, where we compare the output of CQR with the actual 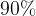

References
[1] Romano, Y., Patterson, E., Candes, E. (2019). Conformalized quantile regression. Advances in neural information processing systems, 32.
[2] Manokhin, V. Awesome conformal prediction Github repo

Leave a comment