An expressive and robust alternative to least square
For regression problems, least square regression (LSR) arguably gets the lion share of data scientists’ attention. The reasons are several: LSR is taught in virtually every introductory statistics course, it is intuitive and is readily available in most of software libraries.
LSR estimates the mean of the predicted variable 

Moreover, ii) LSR is not robust to outliers: the presence of a few “corrupted” points can affect largely the quality of the regression.
Quantile regression (QR) is a method that addresses both concerns i), ii) above:
i) QR it can estimate any quantile of the distribution of the predicted
ii) QR is more robust to the presence of outliers than classic LSR.
Next, we first introduce the notion of (conditional) quantile before delving into QR, via an instructive parallel with LSR.
1. Quantile of a random variable
Let consider a random variable 



This concept can be directly formalized if the cumulative density function (CDF) 
![{\mathcal Q^{\tau}[Y]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal+Q%5E%7B%5Ctau%7D%5BY%5D%7D&bg=ffffff&fg=000000&s=1&c=20201002)
![{\Pr(Y\le \mathcal Q^{\tau}[Y]):=F_Y(\mathcal{Q}^{\tau})=\tau}](https://s0.wp.com/latex.php?latex=%7B%5CPr%28Y%5Cle+%5Cmathcal+Q%5E%7B%5Ctau%7D%5BY%5D%29%3A%3DF_Y%28%5Cmathcal%7BQ%7D%5E%7B%5Ctau%7D%29%3D%5Ctau%7D&bg=ffffff&fg=000000&s=1&c=20201002)
![\displaystyle \mathcal Q^{\tau}[Y] := F_Y^{-1}(q), \quad \mathrm{if } \ F_Y^{-1} \ \mathrm{exists}. \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal+Q%5E%7B%5Ctau%7D%5BY%5D+%3A%3D+F_Y%5E%7B-1%7D%28q%29%2C+%5Cquad+%5Cmathrm%7Bif+%7D+%5C+F_Y%5E%7B-1%7D+%5C+%5Cmathrm%7Bexists%7D.+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=1&c=20201002)
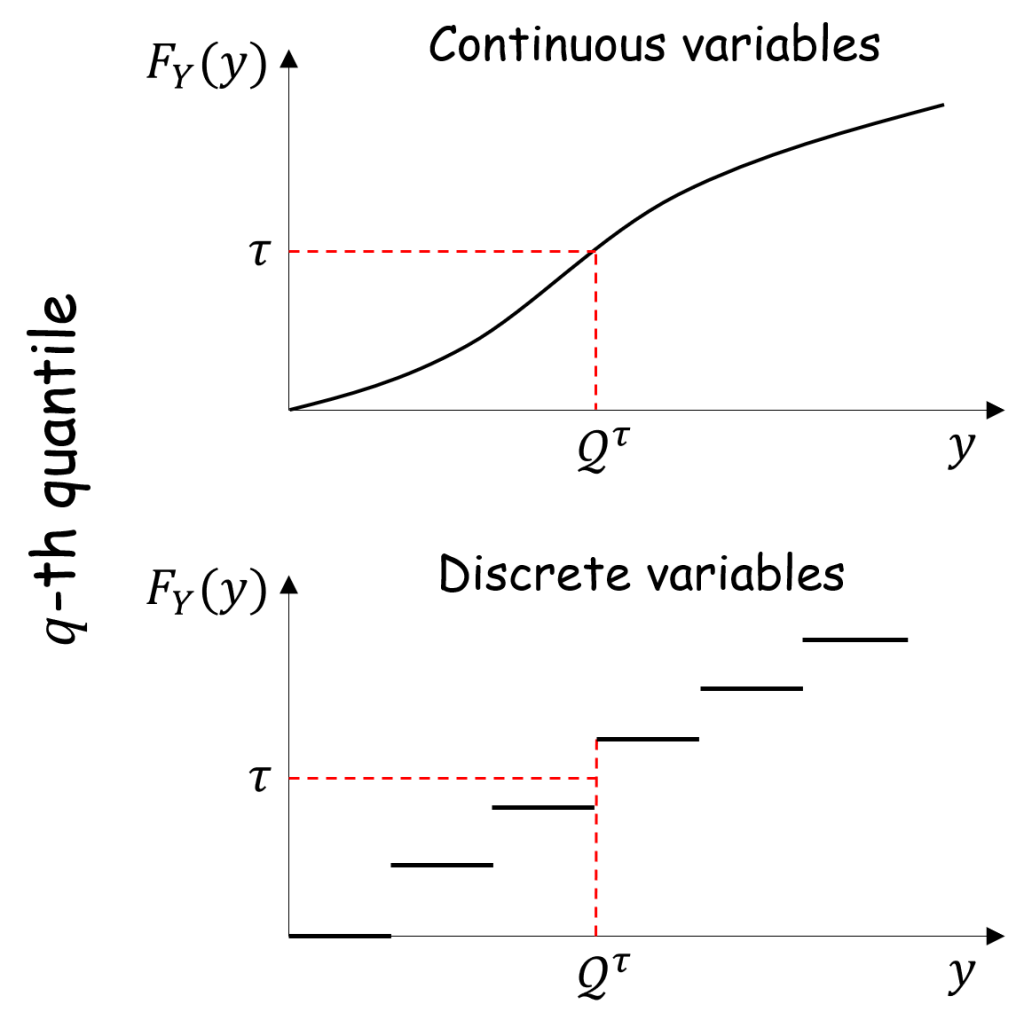
However, for discrete variables, the CDF 


Suppose now that we want to compute the 
To cater for non-invertible CDFs, expression (1) is then generalized as the minimum value at which the cumulative density function exceeds
Definition 1 The
of random variable
![\displaystyle \mathcal{Q}^{\tau}[Y] := \inf \left\{y: \, F_Y(y)\ge \tau \right\}. \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BQ%7D%5E%7B%5Ctau%7D%5BY%5D+%3A%3D+%5Cinf+%5Cleft%5C%7By%3A+%5C%2C+F_Y%28y%29%5Cge+%5Ctau+%5Cright%5C%7D.+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=1&c=20201002)
Thus, in the example above, the
Note also that, when
Estimation. In most practical cases, we do not have access to the CDF 



![\displaystyle \widetilde{Q}^{\tau}[Y] = y_{\lceil \tau n \rceil}. \ \ \ \ \ (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cwidetilde%7BQ%7D%5E%7B%5Ctau%7D%5BY%5D+%3D+y_%7B%5Clceil+%5Ctau+n+%5Crceil%7D.+%5C+%5C+%5C+%5C+%5C+%284%29&bg=ffffff&fg=000000&s=1&c=20201002)
Conditional quantile. Extending the definition of quantile to conditioned random variables is straightforward. Suppose that 



![{\mathcal Q^{\tau}[Y|X=x]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal+Q%5E%7B%5Ctau%7D%5BY%7CX%3Dx%5D%7D&bg=ffffff&fg=000000&s=1&c=20201002)
Definition 2 The
of random variable
![\displaystyle \mathcal{Q}^{\tau}[Y|X=x] := \inf \left\{y: \, F_{Y|X=x}(y)\ge \tau \right\}, \quad \forall x\in \mathcal X. \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BQ%7D%5E%7B%5Ctau%7D%5BY%7CX%3Dx%5D+%3A%3D+%5Cinf+%5Cleft%5C%7By%3A+%5C%2C+F_%7BY%7CX%3Dx%7D%28y%29%5Cge+%5Ctau+%5Cright%5C%7D%2C+%5Cquad+%5Cforall+x%5Cin+%5Cmathcal+X.+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=1&c=20201002)
2. Regression: Quantile vs. Least square
The goal of regression is to estimate a predefined target statistics ![{\mathcal S[Y|X]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal+S%5BY%7CX%5D%7D&bg=ffffff&fg=000000&s=1&c=20201002)
- If such statistic is the conditional mean, i.e.,
, then we obtain the classic least square regression (LSR);
- If such statistic is the
, then we obtain the quantile regression (QR).
Assume now that we have observed 
A naive approach for quantile regression would prescribe, for each 




A better (but still unsatisfactory) approach would be to cluster the observations into bins where the values 
To introduce QR, let us make a step back to analyze general (hence, not necessarily quantile) regression problems.
Let 


![{\mathcal S[Y|X=x]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal+S%5BY%7CX%3Dx%5D%7D&bg=ffffff&fg=000000&s=1&c=20201002)
- Design a loss function
such that the guess function
that minimizes the expected loss is precisely the target statistic
Recall that, produces the statistic
- Define a parametrized class of functions
where
is the vector of parameters.
- If
, where
is the
-th component of
- In case of deep learning,
is the collection of weights and biases of a neural network.
- If
- Minimize the empirical loss:
whereis a potential regularizer, that penalizes extreme values of
).
Finally,is our regressor.
![\displaystyle \mathcal S[Y|X] = \mathrm{argmin}_{h: \mathcal X\rightarrow \mathcal Y} \, \mathbb E_{(X,Y)\sim p_{X,Y}} \ell(Y,h(X)). \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal+S%5BY%7CX%5D+%3D+%5Cmathrm%7Bargmin%7D_%7Bh%3A+%5Cmathcal+X%5Crightarrow+%5Cmathcal+Y%7D+%5C%2C+%5Cmathbb+E_%7B%28X%2CY%29%5Csim+p_%7BX%2CY%7D%7D+%5Cell%28Y%2Ch%28X%29%29.+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=1&c=20201002)

Next we discuss how to go about steps 1 and 3 in the case of LSR and QR.
2.1. Loss function design
To design the appropriate loss function for QR, it is instructive to draw a parallel with its more popular LSR counterpart.

Least squares regression (LSR) draws its name precisely from its loss function, being the square of the residual 

The loss function 


![{\mathbb E[Y|X]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb+E%5BY%7CX%5D%7D&bg=ffffff&fg=000000&s=1&c=20201002)
Theorem 3 The conditional mean
, minimizes the expected loss:
where the expectation is with respect to the joint distribution
of
![\displaystyle \mathbb E[Y|X] = \mathrm{argmin}_{h: \mathcal X\rightarrow \mathcal Y} \, \mathbb E_{(X,Y)\sim p_{X,Y}} \ell^{\mathrm{LSR}}(Y,h(X)) \ \ \ \ \ (9)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5BY%7CX%5D+%3D+%5Cmathrm%7Bargmin%7D_%7Bh%3A+%5Cmathcal+X%5Crightarrow+%5Cmathcal+Y%7D+%5C%2C+%5Cmathbb+E_%7B%28X%2CY%29%5Csim+p_%7BX%2CY%7D%7D+%5Cell%5E%7B%5Cmathrm%7BLSR%7D%7D%28Y%2Ch%28X%29%29+%5C+%5C+%5C+%5C+%5C+%289%29&bg=ffffff&fg=000000&s=1&c=20201002)
Proof: We first prove that, for any fixed 
![\displaystyle \mathbb E_{Y\sim p_{Y|X=x}} \ell^{\mathrm{LSR}}\left(Y,\mathbb E[Y|X=x]\right) \le \mathbb E_{Y\sim p_{Y|X=x}} \ell^{\mathrm{LSR}}\left(Y, h(x)\right). \ \ \ \ \ (10)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E_%7BY%5Csim+p_%7BY%7CX%3Dx%7D%7D+%5Cell%5E%7B%5Cmathrm%7BLSR%7D%7D%5Cleft%28Y%2C%5Cmathbb+E%5BY%7CX%3Dx%5D%5Cright%29+%5Cle+%5Cmathbb+E_%7BY%5Csim+p_%7BY%7CX%3Dx%7D%7D+%5Cell%5E%7B%5Cmathrm%7BLSR%7D%7D%5Cleft%28Y%2C+h%28x%29%5Cright%29.+%5C+%5C+%5C+%5C+%5C+%2810%29&bg=ffffff&fg=000000&s=1&c=20201002)
Hereafter, for simplicity of notation we will omit the dependency on
![\displaystyle \ell^{\mathrm{LSR}}\left(Y,h\right)^2=\mathbb E[Y-h] = \mathbb E\left[ Y - \mathbb E[Y] + \mathbb E[Y] - h \right]^2 \ \ \ \ \ (11)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cell%5E%7B%5Cmathrm%7BLSR%7D%7D%5Cleft%28Y%2Ch%5Cright%29%5E2%3D%5Cmathbb+E%5BY-h%5D+%3D+%5Cmathbb+E%5Cleft%5B+Y+-+%5Cmathbb+E%5BY%5D+%2B+%5Cmathbb+E%5BY%5D+-+h+%5Cright%5D%5E2+%5C+%5C+%5C+%5C+%5C+%2811%29&bg=ffffff&fg=000000&s=1&c=20201002)
![\displaystyle \quad = \mathbb E\left[ Y - \mathbb E[Y] \right]^2 + \mathbb E\left[ \mathbb E[Y] - h \right]^2 + 2 \left(\mathbb E[Y] - h \right) \mathbb E \left[ Y - \mathbb E[Y]\right] \ \ \ \ \ (12)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cquad+%3D+%5Cmathbb+E%5Cleft%5B+Y+-+%5Cmathbb+E%5BY%5D+%5Cright%5D%5E2+%2B+%5Cmathbb+E%5Cleft%5B+%5Cmathbb+E%5BY%5D+-+h+%5Cright%5D%5E2+%2B+2+%5Cleft%28%5Cmathbb+E%5BY%5D+-+h+%5Cright%29+%5Cmathbb+E+%5Cleft%5B+Y+-+%5Cmathbb+E%5BY%5D%5Cright%5D+%5C+%5C+%5C+%5C+%5C+%2812%29&bg=ffffff&fg=000000&s=1&c=20201002)
The second term is nonnegative since ![{(\mathbb E[Y] - h)^2\ge 0}](https://s0.wp.com/latex.php?latex=%7B%28%5Cmathbb+E%5BY%5D+-+h%29%5E2%5Cge+0%7D&bg=ffffff&fg=000000&s=1&c=20201002)
![{\mathbb E \left[ Y - \mathbb E[Y]\right]=0}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb+E+%5Cleft%5B+Y+-+%5Cmathbb+E%5BY%5D%5Cright%5D%3D0%7D&bg=ffffff&fg=000000&s=1&c=20201002)

Quantile regression (QR). Similarly to the LSR case, the loss function for the ![{\mathcal Q^{\tau}[Y|X]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal+Q%5E%7B%5Ctau%7D%5BY%7CX%5D%7D&bg=ffffff&fg=000000&s=1&c=20201002)

Note that, in contrast to LSR, residuals are weighted differently depending on their sign. Moreover, the loss function increases only linearly with the magnitude of the residuals. Interestingly, when our target statistic is the conditional median (i.e., 
Theorem 4 The conditional quantile
![\displaystyle \mathcal Q^{\tau}[Y|X] = \mathrm{argmin}_{h: \mathcal X\rightarrow \mathcal Y} \, \mathbb E_{(X,Y)\sim p_{X,Y}} \ell^{\tau \mathrm{QR}}(Y,h(X)). \ \ \ \ \ (14)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal+Q%5E%7B%5Ctau%7D%5BY%7CX%5D+%3D+%5Cmathrm%7Bargmin%7D_%7Bh%3A+%5Cmathcal+X%5Crightarrow+%5Cmathcal+Y%7D+%5C%2C+%5Cmathbb+E_%7B%28X%2CY%29%5Csim+p_%7BX%2CY%7D%7D+%5Cell%5E%7B%5Ctau+%5Cmathrm%7BQR%7D%7D%28Y%2Ch%28X%29%29.+%5C+%5C+%5C+%5C+%5C+%2814%29&bg=ffffff&fg=000000&s=1&c=20201002)
Proof: We prove the thesis under the assumption that the CDF
![\displaystyle \mathbb E_{Y\sim p_{Y|X=x}} \ell^{\tau\mathrm{QR}}\left(Y,\mathcal Q^{\tau}[Y|X=x]\right) \le \mathbb E_{Y\sim p_{Y|X=x}} \ell^{\tau \mathrm{QR}}\left(Y, h(x)\right). \ \ \ \ \ (15)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E_%7BY%5Csim+p_%7BY%7CX%3Dx%7D%7D+%5Cell%5E%7B%5Ctau%5Cmathrm%7BQR%7D%7D%5Cleft%28Y%2C%5Cmathcal+Q%5E%7B%5Ctau%7D%5BY%7CX%3Dx%5D%5Cright%29+%5Cle+%5Cmathbb+E_%7BY%5Csim+p_%7BY%7CX%3Dx%7D%7D+%5Cell%5E%7B%5Ctau+%5Cmathrm%7BQR%7D%7D%5Cleft%28Y%2C+h%28x%29%5Cright%29.+%5C+%5C+%5C+%5C+%5C+%2815%29&bg=ffffff&fg=000000&s=1&c=20201002)
By omitting the dependency on
![\displaystyle \mathcal Q^{\tau}[Y] = \mathrm{argmin}_h \, (\tau-1) \int_{-\infty}^{z} (y - h) p_Y(y) dy + \tau \int_{z}^{\infty} (y-h) p_Y(y) dy \ \ \ \ \ (16)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal+Q%5E%7B%5Ctau%7D%5BY%5D+%3D+%5Cmathrm%7Bargmin%7D_h+%5C%2C+%28%5Ctau-1%29+%5Cint_%7B-%5Cinfty%7D%5E%7Bz%7D+%28y+-+h%29+p_Y%28y%29+dy+%2B+%5Ctau+%5Cint_%7Bz%7D%5E%7B%5Cinfty%7D+%28y-h%29+p_Y%28y%29+dy+%5C+%5C+%5C+%5C+%5C+%2816%29&bg=ffffff&fg=000000&s=1&c=20201002)
To prove (16) we will take the derivative of the function to be minimized with respect to 


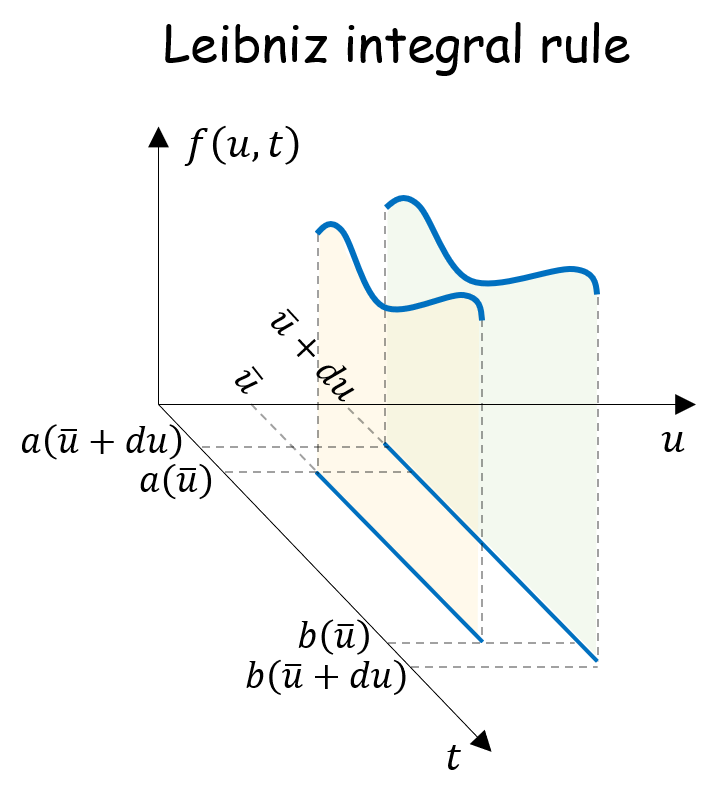
By applying Leibniz rule to the terms in (16) we obtain:
![\displaystyle \frac{d}{dh} \left[ (\tau-1) \int_{-\infty}^{h} (y - h) p_Y(y) dy + \tau \int_{h}^{\infty} (y-h) p_Y(y) dy \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7Bd%7D%7Bdh%7D+%5Cleft%5B+%28%5Ctau-1%29+%5Cint_%7B-%5Cinfty%7D%5E%7Bh%7D+%28y+-+h%29+p_Y%28y%29+dy+%2B+%5Ctau+%5Cint_%7Bh%7D%5E%7B%5Cinfty%7D+%28y-h%29+p_Y%28y%29+dy+%5Cright%5D+&bg=ffffff&fg=000000&s=1&c=20201002)


Thus, the optimal 
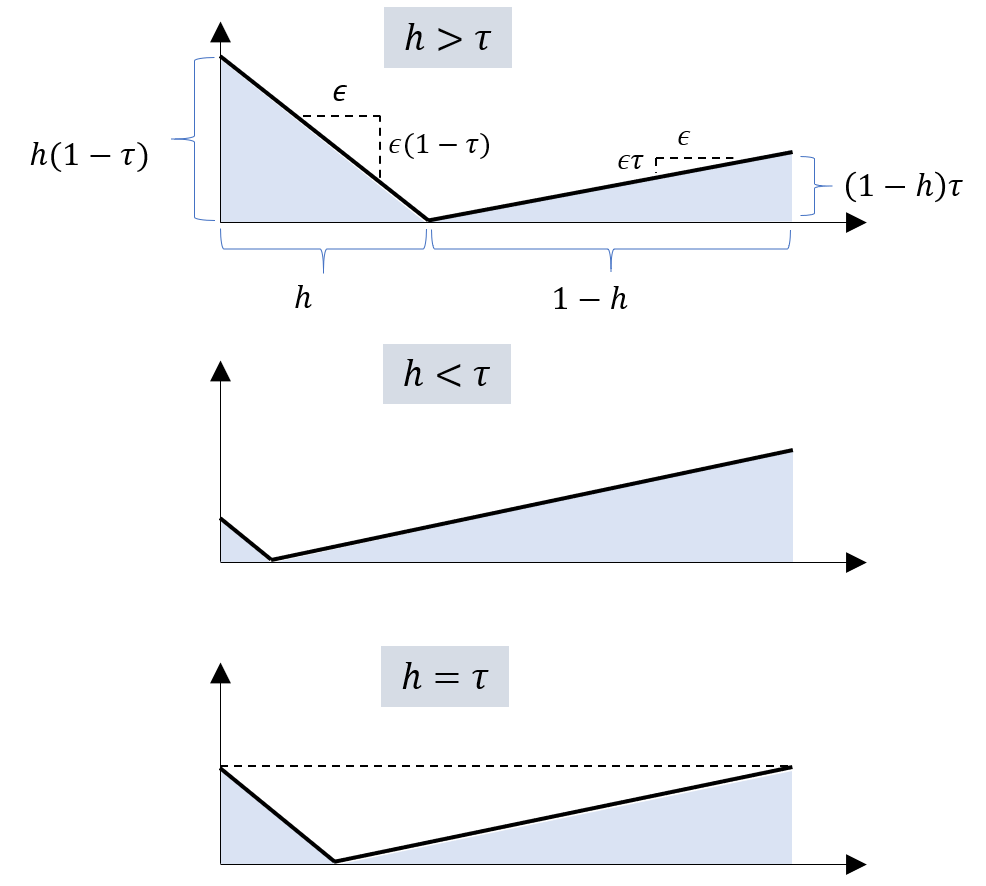
To gain some visual intuitions of the result of Theorem (4), it is useful to consider the simple case where
![\displaystyle \min_{h\in[0,1]} (1-\tau) \int_0^h |y-h| dy + \tau \int_h^1 |y-h| dy \ \ \ \ \ (20)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmin_%7Bh%5Cin%5B0%2C1%5D%7D+%281-%5Ctau%29+%5Cint_0%5Eh+%7Cy-h%7C+dy+%2B+%5Ctau+%5Cint_h%5E1+%7Cy-h%7C+dy+%5C+%5C+%5C+%5C+%5C+%2820%29&bg=ffffff&fg=000000&s=1&c=20201002)
![\displaystyle = \min_{h\in[0,1]} \frac{1}{2}h^2 (1-\tau) + \frac{1}{2}(1-h)^2 \tau \ \ \ \ \ (21)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cmin_%7Bh%5Cin%5B0%2C1%5D%7D+%5Cfrac%7B1%7D%7B2%7Dh%5E2+%281-%5Ctau%29+%2B+%5Cfrac%7B1%7D%7B2%7D%281-h%29%5E2+%5Ctau+%5C+%5C+%5C+%5C+%5C+%2821%29&bg=ffffff&fg=000000&s=1&c=20201002)
By taking the derivative with respect to

2.2. Empirical loss minimization
For simplicity, we here confine ourselves to linear regression, where the guessing function takes the form:

Also, we discard the regularizer, and we aim at solving the empirical average of losses:

Finally, our 
Least square regression (LSR). If the loss 


where 
![{[y^i]_i}](https://s0.wp.com/latex.php?latex=%7B%5By%5Ei%5D_i%7D&bg=ffffff&fg=000000&s=1&c=20201002)


![{[x_i^j]_i}](https://s0.wp.com/latex.php?latex=%7B%5Bx_i%5Ej%5D_i%7D&bg=ffffff&fg=000000&s=1&c=20201002)


When non-linear regression is used, in general there exists no closed-form formula for 
Quantile regression (QR). Even for linear QR, no closed-form formula for the optimal
We first rewrite the residual 








3. Robustness to outliers
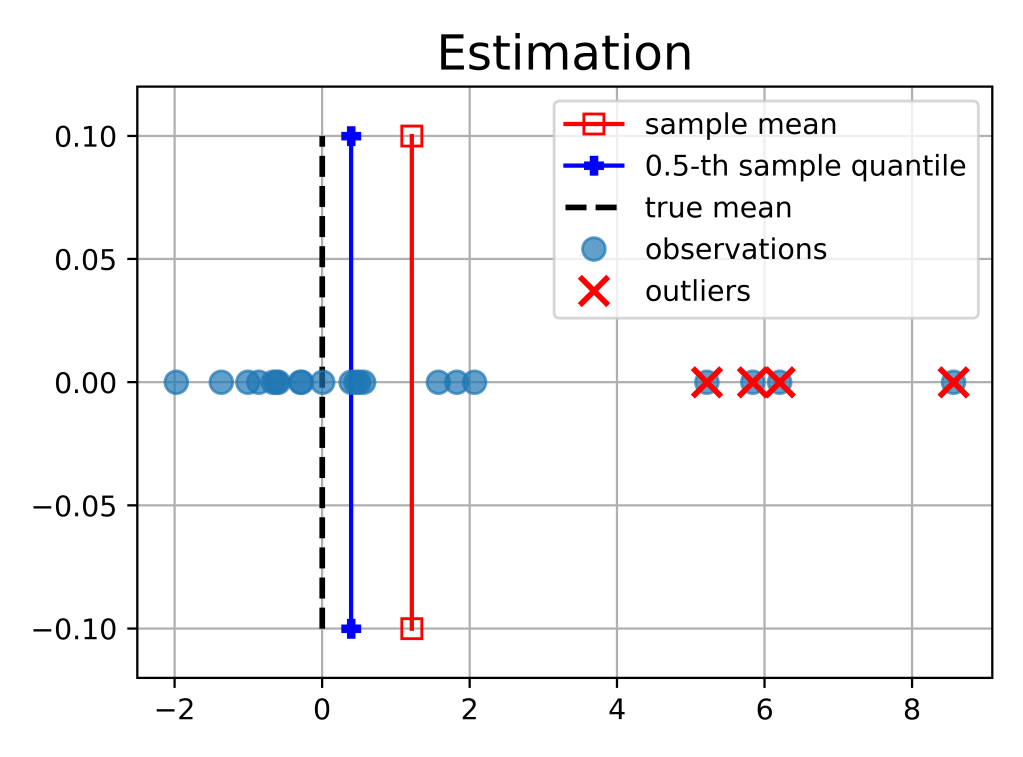
Real data are often messy and may contain extreme “corrupted” values, commonly called outliers. It turns out that both quantile estimation and regression are robust to outliers. We provide some intuitions below.
Estimation. Let us start with the simpler case where the predictor variable 

In contrast, the sample mean 
Importantly, if the distribution of 
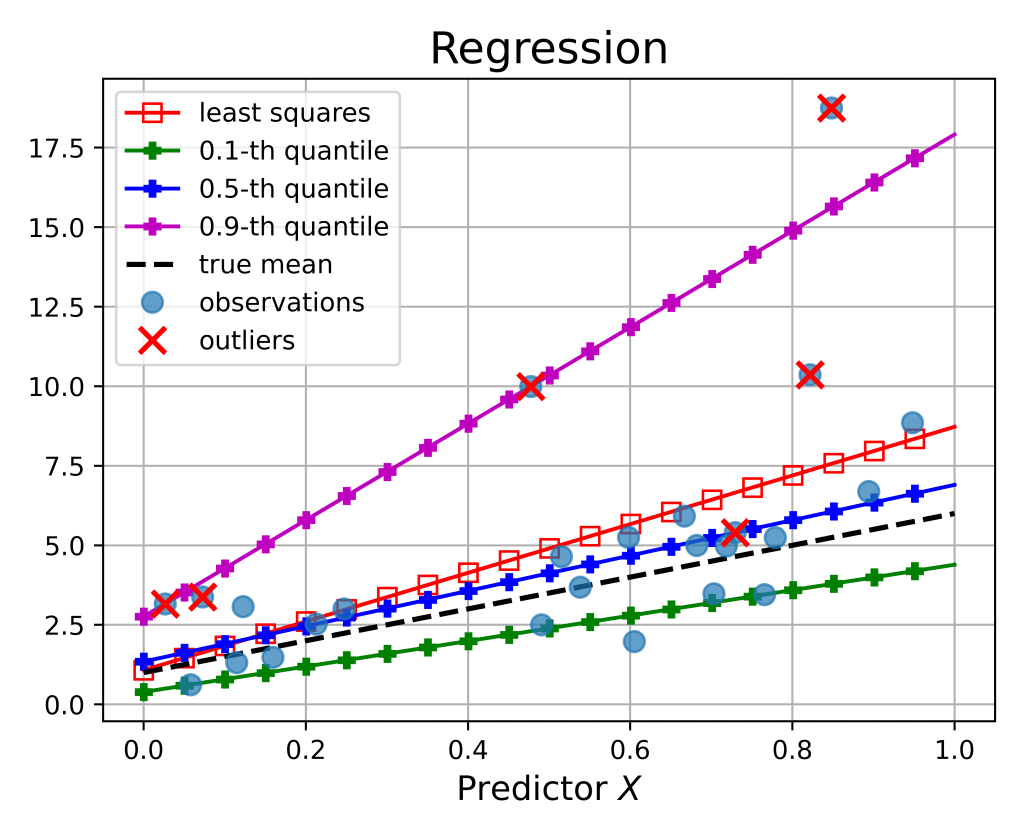
Regression. Once again, it is instructive to draw a parallel between QR and LSR. In the loss function of LSR (8), residuals are squared: if an outlier has a residual being 4 times larger than a non-outlier, then its associated loss is 16 times bigger. On the other hand, the loss in QR (13) is simply proportional to the residual magnitude, hence the outlier would incur a loss being only 4 times higher than the non-outlier.
As a result, in the quest for minimizing its loss, LSR has the natural tendency to “over-react” to the presence of outliers by bringing 
References
[1] Koenker, R. (2005). Quantile regression (Vol. 38). Cambridge university press.
[2] Hao, L., Naiman, D. Q. (2007). Quantile regression (No. 149). Sage.
[3] Scikit-learn Quantile Regressor examples
[4] Scikit-learn Quantile Regressor function
[5] Stackexchange: Formulating Quantile Regression as a Linear Program

Leave a comment