The importance of being uncertainty-aware. When making a prediction (in a regression or a classification setting) based on observed inputs 
![{[\underline{Y},\overline{Y}]}](https://s0.wp.com/latex.php?latex=%7B%5B%5Cunderline%7BY%7D%2C%5Coverline%7BY%7D%5D%7D&bg=ffffff&fg=000000&s=1&c=20201002)
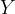
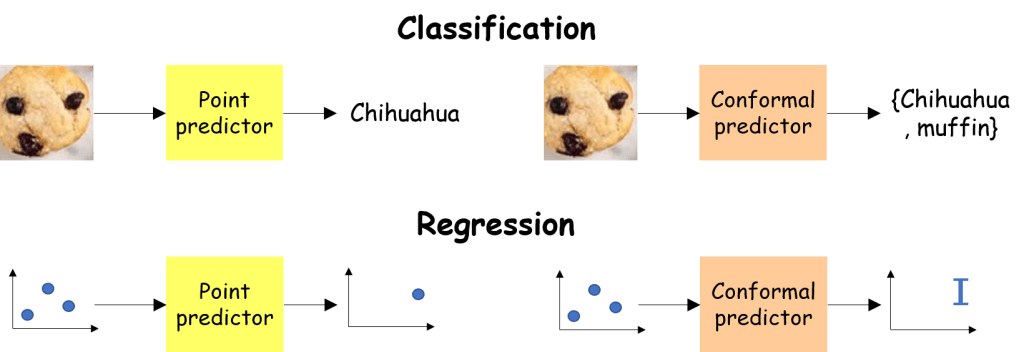
For instance, a trader would be interested in knowing within which boundaries the stock price remains, rather than a single “best guess” price, to anticipate the next move. Else, a doctor examining an MRI (Magnetic Resonance Image) scan would want to know whether a certain illness can be confidently ruled out, and if not, take the necessary actions.
This can be generally achieved via Bayesian models, that assign probability distributions to the model parameters that are updated via Bayes formula as new data is observed.
Although the Bayesian viewpoint has been gaining traction in the last few years, the bulk of ML models out there are still uncertainty-unaware, and point-based. Indeed, after observing the next input 


An elegant method called conformity prediction [1]-[5], based on simple intuitions and math, is able to quantify the uncertainty of any point predictor, with surprisingly low additional effort.
Scenario. Let 




Goal: Coverage. Given a miscoverage level 



where 

A first (dumb) attempt. Imagine that 

Small set property. The example above hints at the fact we not only want to fulfill (1), but we intuitively want 
A second (smarter) attempt. Let us consider regression problems, where the input 

- train the predictor
on all
- compute the residuals
,
- compute the
quantile of the empirical distribution of
, that we call
- output the prediction interval


![{[f(X')-\widetilde{q}; f(X')+\widetilde{q}]}](https://s0.wp.com/latex.php?latex=%7B%5Bf%28X%27%29-%5Cwidetilde%7Bq%7D%3B+f%28X%27%29%2B%5Cwidetilde%7Bq%7D%5D%7D&bg=ffffff&fg=000000&s=1&c=20201002)
Although intuitively sound, such procedure is approximately valid only for a large number of samples, and under certain regularity conditions on the underlying data distribution and the estimator
The main intuition. In the attempt above, there exists a fundamental difference between the points 
Instead, suppose that we randomly split the first 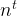


![{[f(X')-\widehat q; f(X')+\widehat q]}](https://s0.wp.com/latex.php?latex=%7B%5Bf%28X%27%29-%5Cwidehat+q%3B+f%28X%27%29%2B%5Cwidehat+q%5D%7D&bg=ffffff&fg=000000&s=1&c=20201002)
Next, we detail the main steps of conformal prediction in the general setting covering regression and classification problems. Finally, we prove its properties.
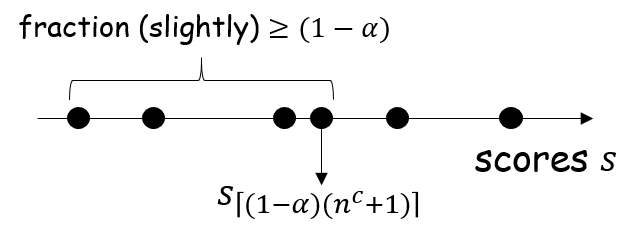
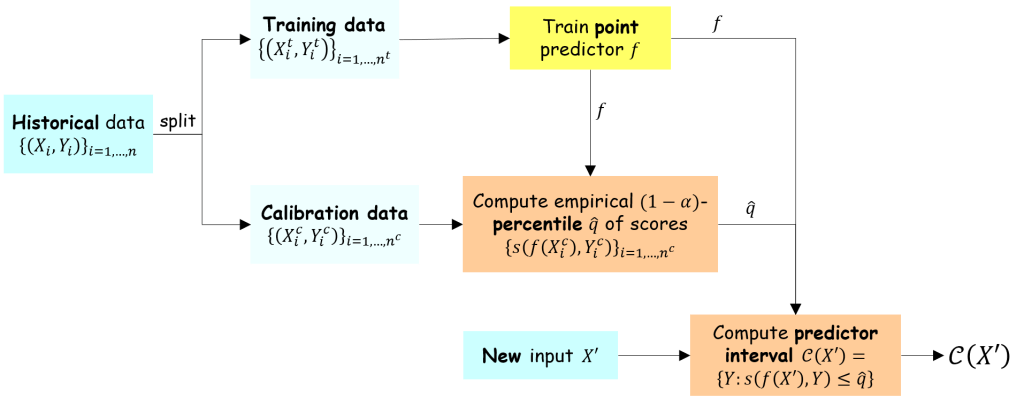
Conformal prediction procedure. Consider a prediction (regression or classification) problem. Given a historical dataset of
- Determine a score function
; lower scores correspond to better predictions
- Randomly split the dataset into training dataset
and calibration dataset
- Train a predictor
- Compute the scores
obtained by the predictor on the calibration set and sort them in increasing order:
- Compute the empirical
- Receive the new input




If the true value
Properties. We first observe that the conformal predictor fulfills the small set size property: the higher the miscoverage
We now show formally that
We start from an intuitive result.
Lemma 1 Assume that the scores
are almost surely distinct and exchangeable, i.e., their joint distribution is not affected by a permutation of the variables. Then,

Proof: We first compute the probability that the score 

![\displaystyle I_0=(-\infty, s_1], \ I_1=(s_1,s_2], \ \dots , \ I_{n^c}=(s_{n^c},\infty)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+I_0%3D%28-%5Cinfty%2C+s_1%5D%2C+%5C+I_1%3D%28s_1%2Cs_2%5D%2C+%5C+%5Cdots+%2C+%5C+I_%7Bn%5Ec%7D%3D%28s_%7Bn%5Ec%7D%2C%5Cinfty%29+&bg=ffffff&fg=000000&s=1&c=20201002)

where 








We remark that i.i.d. variables are also exchangeable. Thus, the exchangeability assumption is looser than the i.i.d. one.
It is perhaps suprisingly easy to derive from Lemma 1 that the conformal prediction fulfills the coverage property (1), as we show below.
Theorem 2 If the scores are exchangeable, then the prediction interval
defined in (3) satisfies:
where the second inequality holds if the scores are almost surely distinct.

Proof: If 






where (10) stems from Lemma 1. By bounding the quantity above as:

we retrieve (7), as desired.
In pratice, the assumption of scores being distinct is not restrictive; in the case that they are not distinct, it suffices to add a (small) i.i.d. noise term to the calibration points and to the new point as well to let the result above hold.
Finally, to satisfy the coverage property (1), it suffices to let the size of the calibration set
That’s (not) all folks! This post covers the main principles underpinning the early work by Vovk et al. [1,2]. However, this post is far from exhaustive and does not include more recent advances on adaptive prediction sets, group balancedness, outlier detection, etc. that one can find in, e.g., [3].
References
[1] Vovk, V. Gammerman, A., Shafer, G. (2005). Algorithmic Learning in a Random World. Springer.
[2] Shafer, G., Vovk, V. (2008). A Tutorial on Conformal Prediction. Journal of Machine Learning Research, 9(3).
[3] Angelopoulos, A. N., Bates, S. (2021). A gentle introduction to conformal prediction and distribution-free uncertainty quantification. arXiv preprint arXiv:2107.07511.
[4] Lei, J., G’Sell, M., Rinaldo, A., Tibshirani, R. J., Wasserman, L. (2018). Distribution-free predictive inference for regression. Journal of the American Statistical Association, 113(523), 1094-1111.

Leave a comment