In signal processing, a classic problem consists in estimating a signal, in the form of a complex column vector 





1. Assumptions
The random signal 
![{\Sigma_x:=\mathbb{E}[x x^{\dagger}]}](https://s0.wp.com/latex.php?latex=%7B%5CSigma_x%3A%3D%5Cmathbb%7BE%7D%5Bx+x%5E%7B%5Cdagger%7D%5D%7D&bg=ffffff&fg=000000&s=1&c=20201002)
![{\Sigma_n:=\mathbb{E}[n n^{\dagger}]}](https://s0.wp.com/latex.php?latex=%7B%5CSigma_n%3A%3D%5Cmathbb%7BE%7D%5Bn+n%5E%7B%5Cdagger%7D%5D%7D&bg=ffffff&fg=000000&s=1&c=20201002)




2. MMSE estimate
The minimum mean squared error (MMSE) estimate is that function 



As already discussed in another post, the MMSE estimate corresponds to the mean of unknown
![\displaystyle \widehat{x}^{\mathrm{MMSE}}(y)=\mathbb{E}[x|y]. \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cwidehat%7Bx%7D%5E%7B%5Cmathrm%7BMMSE%7D%7D%28y%29%3D%5Cmathbb%7BE%7D%5Bx%7Cy%5D.+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=1&c=20201002)
Intuitively, the best (in the MMSE sense) guess for the unknown
2.1. A more specific formula
Since

We can further specialize the expression above by observing that:
![\displaystyle \Sigma_{x,y} = \mathbb{E}\left[ x y^{\dagger} \right] = \mathbb{E}\left[ x x^{\dagger} H^{\dagger} + x n^{\dagger} \right] = H^{\dagger}, \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CSigma_%7Bx%2Cy%7D+%3D+%5Cmathbb%7BE%7D%5Cleft%5B+x+y%5E%7B%5Cdagger%7D+%5Cright%5D+%3D+%5Cmathbb%7BE%7D%5Cleft%5B+x+x%5E%7B%5Cdagger%7D+H%5E%7B%5Cdagger%7D+%2B+x+n%5E%7B%5Cdagger%7D+%5Cright%5D+%3D+H%5E%7B%5Cdagger%7D%2C+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=1&c=20201002)
![\displaystyle \Sigma_{y,y} = \mathbb{E} \left[ y y^{\dagger} \right] = \mathbb{E} \left[ (Hx+n)(x^{\dagger}H^{\dagger} + n^{\dagger}) \right] = H H^\dagger + \Sigma_n. \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CSigma_%7By%2Cy%7D+%3D+%5Cmathbb%7BE%7D+%5Cleft%5B+y+y%5E%7B%5Cdagger%7D+%5Cright%5D+%3D+%5Cmathbb%7BE%7D+%5Cleft%5B+%28Hx%2Bn%29%28x%5E%7B%5Cdagger%7DH%5E%7B%5Cdagger%7D+%2B+n%5E%7B%5Cdagger%7D%29+%5Cright%5D+%3D+H+H%5E%5Cdagger+%2B+%5CSigma_n.+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=1&c=20201002)
Note that in both expressions above we exploited the fact that noise and signal are uncorrelated. By plugging (5) and (6) into (4), we obtain:

3. Let’s simplify our life by whitening the noise
To further simplify (7) it is convenient to whiten the noise, i.e., to deal with an equivalent model where the noise covariance matrix is diagonal. This can be simply achieved by pre-multiplying 




where 



![\displaystyle \mathbb{E}\left[ \widetilde{n} \widetilde{n}^\dagger \right] = \mathbb{E}\left[ \sigma_n\Sigma_n^{-1/2}n n^\dagger\sigma_n \Sigma_n^{-1/2} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5Cleft%5B+%5Cwidetilde%7Bn%7D+%5Cwidetilde%7Bn%7D%5E%5Cdagger+%5Cright%5D+%3D+%5Cmathbb%7BE%7D%5Cleft%5B+%5Csigma_n%5CSigma_n%5E%7B-1%2F2%7Dn+n%5E%5Cdagger%5Csigma_n+%5CSigma_n%5E%7B-1%2F2%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=1&c=20201002)

We can then rewrite (7) in simpler terms as:

By invoking the matrix inversion lemma, we can equivalently write:

4. Corner (but illuminating) cases
To develop a better understanding of how MMSE estimate works, it is interesting to investigate its behavior in a few extreme but important cases.
4.1. Negligible noise and 
We start from the simplest sub-case: in the absence of noise, and assuming that signal and observation have the same size 

4.2. Negligible noise: Pseudoinverse
A natural question arises: what if 

which is the pseudoinverse of
In communication theory, this estimator is also called zero-forcer. In fact, if we pre-multiply the signal 


4.3. Uni-dimensional signal: Matched filter
Let us turn to another simple corner case: we assume the signal 


The signal 
4.4. Orthogonal 
Let us now expand the case above by returning to the original multi-dimensional signal 

In words, to estimate the 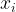

4.5. Noise is overwhelming: No info
From (14),(13) it is apparent that, when the noise drowns the signal, the MMSE estimate tends to zero, whatever the observed signal is. This behavior is supported by intuition: when ![{\mathbb{E}[x]=0}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5Bx%5D%3D0%7D&bg=ffffff&fg=000000&s=1&c=20201002)


References
[1] Kay, S. M. (1993). Fundamentals of statistical signal processing: estimation theory. Prentice-Hall, Inc..

Leave a comment