Gaussian (or normal) variables are all around the place. Their expressive power is certified by the Central Limit Theorem, stating that the mean of independent (and not necessarily Gaussian!) random variables tends to a Gaussian variable. And even when a variable is definitely not Gaussian, it is sometimes convenient to approximate it as one, via Laplace approximation, or to model it as a Gaussian mixture. Gaussian distributions also pop up, e.g., in Bayesian optimization, where an unknown function is modeled as a Gaussian process [1]. And yet, while the uni-variate Gaussian case is simple to grasp (the “bell”!) and the expression of its density function is easy to remember (something like 
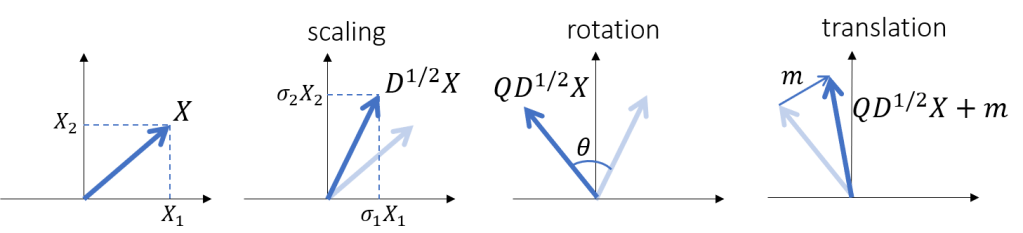
Geometric interpretation. In this post we try to shed some light on multi-variate Gaussian distributions case via a beautiful (and well known) geometric interpretation: any vector of jointly Gaussian variables can be obtained by applying basic geometric operations to a collection of independent standard normal variables (with zeros mean and unit variance), such as 1) scale 2) rotation and 3) translation.
How to read this post. To show that the geometric interpretation holds true we will take no shortcut, and delve first into a couple of preliminary concepts from calculus and linear algebra in Section 1. Yet, the hurried reader can jump directly to Section 2 where we serve the main dish with multi-variate Gaussian variables.
1.1. Change of variables in distributions
Let us first refresh our memory on calculus. Suppose we know the distribution 



We want to figure out the relationship between the distribution 
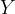
Theorem 1 Let
. Suppose
differentiable and invertible, where
. Then,

Let us inspect expression (1). Its latter term, 







If i)

To obtain 

Else, if ii)

and
![\displaystyle f_Y(y) = \frac{d}{dy} \left[ 1- F_X\left(v(y)\right)\right] = -f_X\left( v(y) \right) \frac{d}{dy} v(y) \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+f_Y%28y%29+%3D+%5Cfrac%7Bd%7D%7Bdy%7D+%5Cleft%5B+1-+F_X%5Cleft%28v%28y%29%5Cright%29%5Cright%5D+%3D+-f_X%5Cleft%28+v%28y%29+%5Cright%29+%5Cfrac%7Bd%7D%7Bdy%7D+v%28y%29+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=1&c=20201002)
We observe that the two cases i) and ii) can be both written as

since 
1.2. Spectral decomposition of symmetric matrices
We now revise another fundamental result, on linear algebra this time: the spectral decomposition of symmetric real matrices, see [3].
Theorem 2 For all
, any symmetric matrix
can be written as the product
, where
is real and unitary (i.e., its rows and columns are all orthogonal:
) and
is a diagonal matrix.
Proof: We split the proof in three parts: 1) 
Part 1: 





where we exploited the property 


Part 2:Each eigenvalue 









Part 3.







![{[v_2,\dots,v_{n+1}]:=V}](https://s0.wp.com/latex.php?latex=%7B%5Bv_2%2C%5Cdots%2Cv_%7Bn%2B1%7D%5D%3A%3DV%7D&bg=ffffff&fg=000000&s=1&c=20201002)

To construct the matrix 


Lastly, we define ![{[v_1, V\widetilde{Q}]}](https://s0.wp.com/latex.php?latex=%7B%5Bv_1%2C+V%5Cwidetilde%7BQ%7D%5D%7D&bg=ffffff&fg=000000&s=1&c=20201002)
![\displaystyle Q^T A Q = \begin{bmatrix} v_1^T \\ \widetilde{Q}^T V^T \end{bmatrix} \widetilde{A} \ [v_1, V\widetilde{Q}] =\begin{bmatrix} v_1^T Av_1^T & v_1^T AV\widetilde{Q} \\ \widetilde{Q}^T V^T A v_1 & \widetilde{Q}^T V^T AV\widetilde{Q} \end{bmatrix} \ \ \ \ \ (10)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Q%5ET+A+Q+%3D+%5Cbegin%7Bbmatrix%7D+v_1%5ET+%5C%5C+%5Cwidetilde%7BQ%7D%5ET+V%5ET+%5Cend%7Bbmatrix%7D+%5Cwidetilde%7BA%7D+%5C+%5Bv_1%2C+V%5Cwidetilde%7BQ%7D%5D+%3D%5Cbegin%7Bbmatrix%7D+v_1%5ET+Av_1%5ET+%26+v_1%5ET+AV%5Cwidetilde%7BQ%7D+%5C%5C+%5Cwidetilde%7BQ%7D%5ET+V%5ET+A+v_1+%26+%5Cwidetilde%7BQ%7D%5ET+V%5ET+AV%5Cwidetilde%7BQ%7D+%5Cend%7Bbmatrix%7D+%5C+%5C+%5C+%5C+%5C+%2810%29&bg=ffffff&fg=000000&s=1&c=20201002)
Let us first inspect the diagonal blocks. Since 



which proves the thesis for matrices 

1.3. Eigenvalues of positive semi-definite matrices
This third and last part of our warm-up section refines the result above for positive semi-definite matrices. A (real) matrix 

![{C=\mathbb{E}[X-\mathbb{E}[X]] \mathbb{E}[X-\mathbb{E}[X]]^T}](https://s0.wp.com/latex.php?latex=%7BC%3D%5Cmathbb%7BE%7D%5BX-%5Cmathbb%7BE%7D%5BX%5D%5D+%5Cmathbb%7BE%7D%5BX-%5Cmathbb%7BE%7D%5BX%5D%5D%5ET%7D&bg=ffffff&fg=000000&s=1&c=20201002)
![\displaystyle x^T C x=x^T \mathbb{E}[X-\mathbb{E}[X]] \mathbb{E}[X-\mathbb{E}[X]]^T x \ \ \ \ \ (12)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+x%5ET+C+x%3Dx%5ET+%5Cmathbb%7BE%7D%5BX-%5Cmathbb%7BE%7D%5BX%5D%5D+%5Cmathbb%7BE%7D%5BX-%5Cmathbb%7BE%7D%5BX%5D%5D%5ET+x+%5C+%5C+%5C+%5C+%5C+%2812%29&bg=ffffff&fg=000000&s=1&c=20201002)
![\displaystyle \quad = (\mathbb{E}[X-\mathbb{E}[X]]^T x)^2\ge 0, \quad \forall\, x \ \ \ \ \ (13)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cquad+%3D+%28%5Cmathbb%7BE%7D%5BX-%5Cmathbb%7BE%7D%5BX%5D%5D%5ET+x%29%5E2%5Cge+0%2C+%5Cquad+%5Cforall%5C%2C+x+%5C+%5C+%5C+%5C+%5C+%2813%29&bg=ffffff&fg=000000&s=1&c=20201002)
We next show that, if the symmetric matrix
Theorem 3 The eigenvalues of a symmetric positive semi-definite matrix are all non-negative.
Proof: We compute 








By the orthogonality property of 




By hypothesis, 


2. The main dish: Gaussian variables
After such a warm-up, we can address the main topic of this post: multi-variate Gaussian variables. Next we show the two-way relationship between independent and correlated Gaussian variables:
- independent
correlated: by scaling, rotating and translating independent standard (i.e., with zero mean and unit variance) Gaussian variables we still obtain Gaussian variables, correlated with each other (Section 2.1)
- correlated

2.1. From independent standard to correlated Gaussian variables
Consider a list ![{X=[X_1,\dots,X_n]}](https://s0.wp.com/latex.php?latex=%7BX%3D%5BX_1%2C%5Cdots%2CX_n%5D%7D&bg=ffffff&fg=000000&s=1&c=20201002)

Since all variables are independent, the multi-variate pdf of the whole vector


To spice things up, let us transform
- scale, obtained by multiplying each
(this is without loss of generality:
and
have the same distribution!). In matricial form, the result of scale is
, where
is a diagonal matrix carrying
will come in handy in the following);
- rotation, resulting from multiplying the scaled vector
. In two dimensions (
),
We will see that these first two operations introduce correlation across different elements of the random vector - translation, by simply adding a constant offset
to the scaled and rotated vector
.

The resulting random vector

To compute the pdf of
- compute the inverse function
, mapping
- compute the determinant of the Jacobian
. By exploiting the property
we deduce that:
where the last expression stems from(in fact,
, hence
).


We can finally exploit Theorem 1 to transform the pdf of the independent standard variables

![\displaystyle \qquad = (2\pi)^{-\frac{n}{2}} |\det(D^{-\frac{1}{2}})| \exp\left[ \left(D^{-\frac{1}{2}} Q^T(y-\mu)\right)^T D^{-\frac{1}{2}} Q^T(y-\mu) \right] \ \ \ \ \ (23)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cqquad+%3D+%282%5Cpi%29%5E%7B-%5Cfrac%7Bn%7D%7B2%7D%7D+%7C%5Cdet%28D%5E%7B-%5Cfrac%7B1%7D%7B2%7D%7D%29%7C+%5Cexp%5Cleft%5B+%5Cleft%28D%5E%7B-%5Cfrac%7B1%7D%7B2%7D%7D+Q%5ET%28y-%5Cmu%29%5Cright%29%5ET+D%5E%7B-%5Cfrac%7B1%7D%7B2%7D%7D+Q%5ET%28y-%5Cmu%29+%5Cright%5D+%5C+%5C+%5C+%5C+%5C+%2823%29&bg=ffffff&fg=000000&s=1&c=20201002)
![\displaystyle \qquad = (2\pi)^{-\frac{n}{2}} |\det(D^{-\frac{1}{2}})| \exp\left[ (y-\mu)^T Q D^{-1} Q^T(y-\mu) \right] \ \ \ \ \ (24)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cqquad+%3D+%282%5Cpi%29%5E%7B-%5Cfrac%7Bn%7D%7B2%7D%7D+%7C%5Cdet%28D%5E%7B-%5Cfrac%7B1%7D%7B2%7D%7D%29%7C+%5Cexp%5Cleft%5B+%28y-%5Cmu%29%5ET+Q+D%5E%7B-1%7D+Q%5ET%28y-%5Cmu%29+%5Cright%5D+%5C+%5C+%5C+%5C+%5C+%2824%29&bg=ffffff&fg=000000&s=1&c=20201002)
We reached our goal but we are quite not satisfied yet: the last formula does not look like what we usually find in textbooks, e.g., [1]. Let us then conveniently define the matrix 


After realizing that 
![\displaystyle f_Y(y) = (2\pi)^{-\frac{n}{2}} |\det(\Sigma^{-\frac{1}{2}})| \exp\left[ (y-\mu)^T \Sigma^{-1} (y-\mu) \right]. \ \ \ \ \ (27)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+f_Y%28y%29+%3D+%282%5Cpi%29%5E%7B-%5Cfrac%7Bn%7D%7B2%7D%7D+%7C%5Cdet%28%5CSigma%5E%7B-%5Cfrac%7B1%7D%7B2%7D%7D%29%7C+%5Cexp%5Cleft%5B+%28y-%5Cmu%29%5ET+%5CSigma%5E%7B-1%7D+%28y-%5Cmu%29+%5Cright%5D.+%5C+%5C+%5C+%5C+%5C+%2827%29&bg=ffffff&fg=000000&s=1&c=20201002)
The vector
![\displaystyle \mathbb{E} [Y] = \mathbb{E}[QD^{\frac{1}{2}}X+\mu] = QD^{\frac{1}{2}}\mathbb{E}[X]+\mu=\mu \ \ \ \ \ (28)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D+%5BY%5D+%3D+%5Cmathbb%7BE%7D%5BQD%5E%7B%5Cfrac%7B1%7D%7B2%7D%7DX%2B%5Cmu%5D+%3D+QD%5E%7B%5Cfrac%7B1%7D%7B2%7D%7D%5Cmathbb%7BE%7D%5BX%5D%2B%5Cmu%3D%5Cmu+%5C+%5C+%5C+%5C+%5C+%2828%29&bg=ffffff&fg=000000&s=1&c=20201002)
![\displaystyle \mathbb{E}\left[(Y-\mu)(Y-\mu)^T\right] = \mathbb{E}\left[ Q D^{\frac{1}{2}} X X^T (D^{\frac{1}{2}})^T Q^T \right] \ \ \ \ \ (29)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5Cleft%5B%28Y-%5Cmu%29%28Y-%5Cmu%29%5ET%5Cright%5D+%3D+%5Cmathbb%7BE%7D%5Cleft%5B+Q+D%5E%7B%5Cfrac%7B1%7D%7B2%7D%7D+X+X%5ET+%28D%5E%7B%5Cfrac%7B1%7D%7B2%7D%7D%29%5ET+Q%5ET+%5Cright%5D+%5C+%5C+%5C+%5C+%5C+%2829%29&bg=ffffff&fg=000000&s=1&c=20201002)
![\displaystyle \qquad = Q D^{\frac{1}{2}} \mathbb{E}\left[ X X^T\right] D^{\frac{1}{2}} Q^T = Q D Q^T=\Sigma. \ \ \ \ \ (30)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cqquad+%3D+Q+D%5E%7B%5Cfrac%7B1%7D%7B2%7D%7D+%5Cmathbb%7BE%7D%5Cleft%5B+X+X%5ET%5Cright%5D+D%5E%7B%5Cfrac%7B1%7D%7B2%7D%7D+Q%5ET+%3D+Q+D+Q%5ET%3D%5CSigma.+%5C+%5C+%5C+%5C+%5C+%2830%29&bg=ffffff&fg=000000&s=1&c=20201002)
since ![{\mathbb{E}[X]=0}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5BX%5D%3D0%7D&bg=ffffff&fg=000000&s=1&c=20201002)
![{\mathbb{E}[ X X^T]=I}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5B+X+X%5ET%5D%3DI%7D&bg=ffffff&fg=000000&s=1&c=20201002)
2.2. From correlated to independent standard Gaussian variables
In this last section we take the reverse path and, given a vector of Gaussian variables 
Take-home message: Suppose you are given a set of Gaussian variables 
References
[1] Bishop, C. (2006). Pattern recognition and machine learning. Springer.
[2] Billingsley, P. (2017). Probability and measure. John Wiley & Sons.
[3] Strang, G. (2022). Introduction to linear algebra. Wellesley-Cambridge Press.

Leave a comment