Policy gradient method are widely used in the Reinforcement Learning settings. In this post we build policy gradient from the ground up, starting from the easier static scenario first, where we maximize a reward function depending solely on our control variable . In subsequent posts, we will turn our attention to the contextual bandit setting, where the reward also depends on a “state” that evolves. Finally, we will turn to the “full-blown” Reinforcement Learning scenario, where state evolves endogenously, as a function of the control variable.
1. Main procedure
Suppose that we want to maximize a function :
The function is initially unknown and can be observed via noisy measurements that we denote by . Noise is supposed i.i.d. across consecutive samplings and has zero mean, such that for all .
There exist in the literature several methods to maximize , called derivative-free (since the gradient of is not directly accessible) or black-box (as we just learn about about its input-output behavior), such as Bayesian optimization [1] or Nelder-Mead algorithm [2]. In policy gradient, instead of optimizing the input variable directly, we rather consider a stochastic policy that defines the probability of selecting , defined by some parameters ; then, we optimize instead, via gradient ascent.
When the policy is used, we call the corresponding average reward:
Our goal is to optimize by performing gradient ascent on . The gradient of with respect to the parameters can be expressed as:
where in (5) we exploit the relation . Note that equation (5) is the expectation with respect to the observation noise and of the control variable of the noisy measurements multiplied by the gradient of , i.e.,
Hence, via a simple trick, we have transformed our problem of evaluating the integral (3), which would require to know the function everywhere (which is clearly in contrast with our assumptions!) to a different problem involving the calculating an expectation.
The good news is that such expectation can be approximated by randomly sampling the function at points drawn from distribution . Yet, before crying victory, we still need to check if we are allowed to approximate (6) and still apply gradient descent to converge to a (local) optimum of . Fortunately, this is the case, as Stochastic Gradient Ascent [3] teaches us. Thus, one can sample points , and update as:
where is the learning rate [3], that must converge to 0 but “not too fast” ( and , e.g., ).
To recap, the (basic) policy gradient procedure is:
Define policy and initialize ,
Draw from
Observe the corresponding samples
Update
Increment and return to 2).
1.1. A concrete example: Gaussian policy
A natural choice for the parametrized policy is the multi-variate Gaussian distribution where the parameters consist of the mean vector and covariance matrix . More explicitly,
To compute the gradient of we exploit the following linear algebra properties:
along with the fact that the inverse of a symmetric matrix is also symmetric. Then, we can compute:
The uni-variate case. To gather intuitions on how policy gradient works in practice, we investigate the uni-dimensional case (). Here, and boil down to the uni-dimensional mean and variance , respectively, thus . Expressions (13), (14) simplify, and the parameter update in (7) becomes:
Let us have a look at (15) first. We observe that the mean moves by a quantity proportional to imbalance between the (weighted) sampled rewards at the right of and at its left:
Second, we notice that the rewards are weighted by a coefficient whose magnitude is the distance from the current . This compensates the fact that, as moves away from , the probability of being chosen by vanishes.
Let us now turn to the variance update formula (16). The variances gets updated by a quantity proportional to
where . Hence, the variance increases if the rewards collected “far” (i.e., more than away) from current mean exceed the rewards collected “near” (i.e., less than away from) . Rewards are weighted by a coefficient that amplifies rewards that are collected far from the “boundary” .
2. Variance reduction: The baseline trick
Although is an unbiased estimator of (hence, the parameter update in (7) converges almost surely to the optimal ), its variance may still be large, which leads to an erratic evolution of parameters across iterations .
The following crucial observation serves us well: by subtracting a constant baseline from the collected rewards , the resulting estimator:
is still unbiased and, if is well chosen, has considerably lower variance than the original estimator.
which proves that, in expectation, the new estimator (19) still equals the gradient of the expected reward.
By computing the derivative of (24) with respect to the baseline and setting it to zero, we obtain the value of the baseline that minimizes the variance of the new estimator (19) as:
Once again, one can estimate by sampling. In practice, even a poor estimation of helps with the gradient ascent stability, and does not jeopardize its unbiasednes, as we saw earlier.
For the interested reader, [4] offers a great introduction to policy gradient algorithms.
References
[1] Shahriari, B., Swersky, K., Wang, Z., Adams, R. P., De Freitas, N. (2015). Taking the human out of the loop: A review of Bayesian optimization. Proceedings of the IEEE, 104(1), 148-175.
[2] Nelder, J. A., Mead, R. (1965). A simplex method for function minimization. The computer journal, 7(4), 308-313.
[3] Bottou, L. (1998). Online algorithms and stochastic approximations. Online learning in neural networks.
[4] Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction. MIT press.






![{\mathbb E[\widetilde{r}(x)]=r(x)}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb+E%5B%5Cwidetilde%7Br%7D%28x%29%5D%3Dr%28x%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)









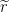

![\displaystyle \nabla_\theta J(\theta) = \mathbb E_{\epsilon,x\sim \pi_\theta(x)} \, \big[ \widetilde{r}(x) \nabla_\theta \log\pi_\theta(x) \big]. \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cnabla_%5Ctheta+J%28%5Ctheta%29+%3D+%5Cmathbb+E_%7B%5Cepsilon%2Cx%5Csim+%5Cpi_%5Ctheta%28x%29%7D+%5C%2C+%5Cbig%5B+%5Cwidetilde%7Br%7D%28x%29+%5Cnabla_%5Ctheta+%5Clog%5Cpi_%5Ctheta%28x%29+%5Cbig%5D.+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=1&c=20201002)

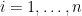

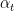



and initialize
,
from
and return to 2).















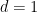


![{\theta:=[m,\sigma^2]}](https://s0.wp.com/latex.php?latex=%7B%5Ctheta%3A%3D%5Bm%2C%5Csigma%5E2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle \sigma^2_{t+1} = \sigma^2_t - \frac{\alpha_t}{2\sigma_t^2} \sum_{i=1}^n \left[1-\left(\tfrac{x_i-m_t}{\sigma_t}\right)^2\right] \widetilde{r}(x_i) \ \ \ \ \ (16)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csigma%5E2_%7Bt%2B1%7D+%3D+%5Csigma%5E2_t+-+%5Cfrac%7B%5Calpha_t%7D%7B2%5Csigma_t%5E2%7D+%5Csum_%7Bi%3D1%7D%5En+%5Cleft%5B1-%5Cleft%28%5Ctfrac%7Bx_i-m_t%7D%7B%5Csigma_t%7D%5Cright%29%5E2%5Cright%5D+%5Cwidetilde%7Br%7D%28x_i%29+%5C+%5C+%5C+%5C+%5C+%2816%29&bg=ffffff&fg=000000&s=1&c=20201002)






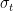





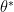



![\displaystyle \mathbb E_{\epsilon,x\sim \pi_\theta(x)} \, \big[ (\widetilde{r}(x)-b) \nabla_\theta \log\pi_\theta(x) \big] = \int (r(x)-b) \nabla_\theta \pi_\theta(x) dx \ \ \ \ \ (20)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E_%7B%5Cepsilon%2Cx%5Csim+%5Cpi_%5Ctheta%28x%29%7D+%5C%2C+%5Cbig%5B+%28%5Cwidetilde%7Br%7D%28x%29-b%29+%5Cnabla_%5Ctheta+%5Clog%5Cpi_%5Ctheta%28x%29+%5Cbig%5D+%3D+%5Cint+%28r%28x%29-b%29+%5Cnabla_%5Ctheta+%5Cpi_%5Ctheta%28x%29+dx+%5C+%5C+%5C+%5C+%5C+%2820%29&bg=ffffff&fg=000000&s=1&c=20201002)



![\displaystyle \mathrm{Var} \big[ (\widetilde{r}(x)-b) \nabla_\theta \log\pi_\theta(x) \big] = \mathbb{E} \left[ (\widetilde{r}(x)-b)^2 (\nabla_\theta \log\pi_\theta(x))^2 \right] -\left(\mathbb{E} \left[ (\widetilde{r}(x)-b) (\nabla_\theta \log\pi_\theta(x)) \right]\right)^2. \ \ \ \ \ (24)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7BVar%7D+%5Cbig%5B+%28%5Cwidetilde%7Br%7D%28x%29-b%29+%5Cnabla_%5Ctheta+%5Clog%5Cpi_%5Ctheta%28x%29+%5Cbig%5D+%3D+%5Cmathbb%7BE%7D+%5Cleft%5B+%28%5Cwidetilde%7Br%7D%28x%29-b%29%5E2+%28%5Cnabla_%5Ctheta+%5Clog%5Cpi_%5Ctheta%28x%29%29%5E2+%5Cright%5D+-%5Cleft%28%5Cmathbb%7BE%7D+%5Cleft%5B+%28%5Cwidetilde%7Br%7D%28x%29-b%29+%28%5Cnabla_%5Ctheta+%5Clog%5Cpi_%5Ctheta%28x%29%29+%5Cright%5D%5Cright%29%5E2.+%5C+%5C+%5C+%5C+%5C+%2824%29&bg=ffffff&fg=000000&s=1&c=20201002)



Leave a comment